GFS 再分析數據批次轉檔
Table of contents
背景
- GFS再分析數據的年期範圍較小(2015~),解析度也較差(0.25度約20Km)。然而因具有行星邊界層數據,是EARR沒有的,因此,也須加以處理。因程式邏輯完全一樣,此處以差異的方式介紹。
- 目標雖然是鄉鎮區平均,但因為GFS解析度20公里(0.25度),需要內插。新網格系統參照tempTW.nc,公版模式範圍、解析度為1Km。
- 內插採用
scipy.interpolate.griddata模組(參考Near Real Time的檔案處理),使用cubic spline,以使空間的變化趨勢較為平緩。
gfs2csv程式說明
執行方式
for yr in 20{16..22};do sub python gfs2csv.py $yr;done
- gfs數據檔格式是grib2,此處應用ncl提供的轉換軟體
ncl_convert2nc將其轉換為nc檔,便於程式讀取。
#kuang@DEVP /nas2/cmaqruns/2019TZPP/output/Annual/aTZPP/gfs_hpbl
#$ diff EARR2csv.py gfs2csv.py
8a9,10
> #utilities
> grb2nc='/opt/anaconda3/envs/ncl_stable/bin/ncl_convert2nc'
gfs2csv IO’s
- 引數:仍為4碼年期
- 舊座標系統的模板:
fname='gfs.0p25.temp.nc' - grib2檔案目錄
- 全部都在一處
- 注意:NCEP可能會遺漏檔案。補遺方式:以前一天同一時間檔案替代(程式不會確認檔案內之時間標籤)。
座標轉換
- gfs檔案的經緯度是1維的向量
- 需先將其展開成2維、再進行座標轉換。
25c27
< fname='slev/EARR.slev.20100606.t12z.nc'
---
> fname='gfs.0p25.temp.nc'
28c30
< for v in V0[1]:
---
> for v in V0[0]:
30c32
< V0=[i for i in V0[1] if i[0] != 'l']+['precip_acc6h']
---
> V0=[i for i in V0[1]]
31a34
> lon,lat=np.meshgrid(lon_0, lat_0)
檔案及迴圈管理
- 檔案目錄及檔名管理:較為單純
57,59c60,62
< dirs=['slev','precip']
< tail={'slev':'.nc','precip':'.f06h.nc'}
< ndiv={'slev':4,'precip':1}
---
> dirs=['./']
> tail={'./':'.f000.grib2'}
> ndiv={'./':4}
- 檔名規則略有差異
- 在讀取前需先進行轉換、再讀入nc檔
67c70,72
< fname=d+'/EARR.'+d+'.'+nowd+'.t{:02d}z'.format(h)+tail[d]
---
> fname=d+'gfs.0p25.'+nowd+'{:02d}'.format(h)+tail[d]
> os.system(grb2nc+' '+fname+'>& /dev/null')
> fname=fname.replace('grib2','nc')
後處理與輸出
- 沒有降雨量
77,79d81
< precip=df['precip_acc6h']
< precip=np.where(precip>=0,precip,0)
< df['precip_acc6h']=precip
- 輸出檔名的差異
88c90
< df0.set_index('YMD').to_csv('EARR'+yr+'.csv')
---
> df0.set_index('YMD').to_csv('GFS'+yr+'.csv')
gfs2csv程式下載
Download: gfs2csv.py
結果
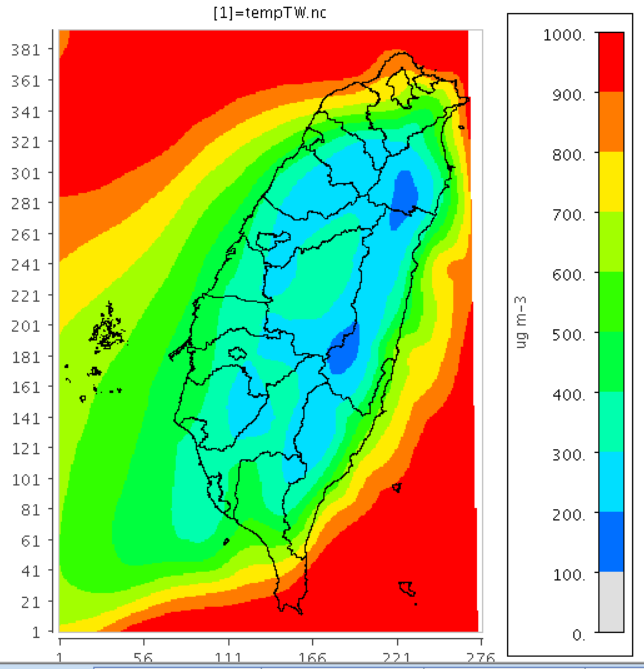 | 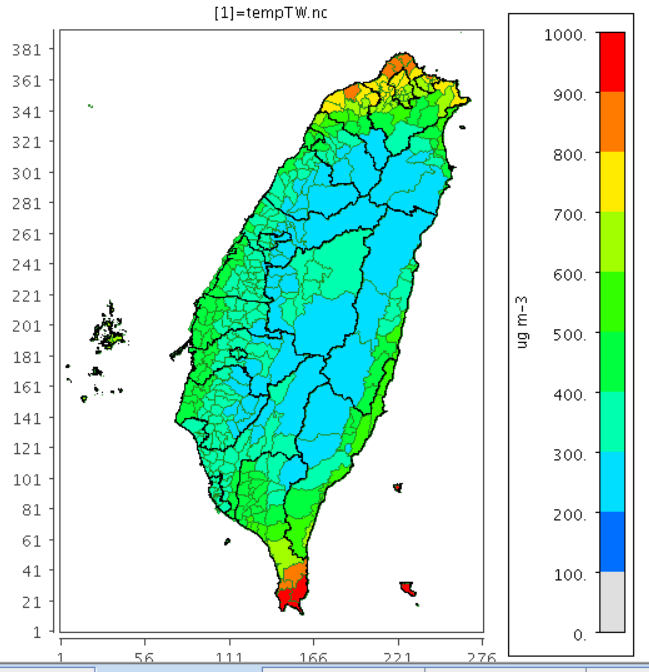 |
| GFS再分析檔案中的行星邊界層高度。單位m | 同左,但為鄉鎮區平均值 |