高公局車行時間預測數據之批次下載
Table of contents
背景
- 高速公路局對外提供未來任意日時、10條路線、共228個匝道出入口作為起、迄端之行車時間預測(高速公路1968)。
- 該預測時間與路況相關,具有未來交通量之參考價值。唯數據並未提供批次下載,須一一點擊選單後執行「立即規劃行程」,方能得知。
- 此處以selenium(4.9.1版)與BeautifulSoup(4.12.2版、一般簡稱bs4)作為下載與解析之模組,並將結果存成csv檔案。
- 介紹selenium的文章有很多,Selenium with Python中文翻译文档這篇算是完整、更新至第4版、也有支援中文。
- bs4的說明介紹也不少,wikipedia有綜合比較各個html解析器的版本、授權、語言、連結等項目。
- 由於高公局所建立的模型雖然還能保持線性、但因維度太多,還需要進行整併、或均化,以利多維度之分析。
- 程式見於github
 |
|---|
| 高公局行車時間預測選單與執行 |
 |
|---|
| 前後共7個出發時間的旅行時間預測結果 |
程式說明
geckodriver之預備
- 由於selenium是靠著Firefox介面來驅動程式,需要有
/usr/bin/geckodriver檔案,該檔案版本與Firefox的版本有密切關係,須先了解firefox的版本,再行選擇下載,詳見github/mozilla/geckodriver。 - 本次執行作業使用Firefox為102.11版,因此選用geckodriver 0.31.0版(2022年4月版本)
模組相依性
- 使用模組如下。
- 由於selenium的尋找指令(
find_element)在3版與4版之間有很大的差異。此處使用4版。
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import os
import json
from pandas import DataFrame
from selenium import webdriver
import datetime
import time
import codecs
import numpy as np
點選相關基本副程式
- 這組沿用以前的程式碼。改成4版2個引數的做法。
def clkid(ID): #click the id
button_element = driver.find_element("id",ID)
button_element.click()
return
def clkpath(ID): #click the xpath (no use)
button_element = driver.find_element(By.XPATH,ID)
button_element.click()
return
def SelectByIDnValue(ID,v): #click and select by value
select = Select(driver.find_element(By.ID,ID))
select.select_by_index(v)
return
主要點選副程式
- 這支為主要點選、輸入、以及執行預測、下載畫面、解讀結果等等動作順序
- 需要引數分別為日、時、高速公路路線序號(1~10)、起訖匝道(序號)
- 佔存html檔約有1.2M。只解讀其中的車行時間預測,共7個時間。
def click_run_save(d,t,w,s1,s2):
day=datetime.date.today()+datetime.timedelta(days=d)
clkid("tripFuturePickDate")
driver.find_element(By.ID,"tripFuturePickDate").clear()
input_1=driver.find_element(By.ID,"tripFuturePickDate")
input_1.send_keys(day.strftime("%Y/%m/%d"))
clkid("tripFuturePickTime")
SelectByIDnValue("tripFuturePickTime",t)
clkid("freeway_from")
SelectByIDnValue("freeway_from",w)
clkid("section_from")
SelectByIDnValue("section_from",s1)
clkid("freeway_from")
SelectByIDnValue("freeway_end",w)
clkid("section_from")
SelectByIDnValue("section_end",s2)
clkpath('//button[@class="button_primary tripplan_btn"]')
if abs(s1-s2) >10:time.sleep(5)
n = os.path.join("/nas2/kuang/tp_future", "results.html")
f = codecs.open(n, "w", "utf−8")
h = driver.page_source
f.write(h)
fn=open('results.html','r')
soup = BeautifulSoup(fn,'html.parser')
span=[str(i) for i in list(soup.find_all('span'))]
lags=[i.split('約')[1].split('分')[0]+'分' for i in span if '約' in i]
return lags
- 該網頁雖然提供了月曆以供選擇日期,也可以直接鍵入格式化日期。因此需先清除既有內容(
.clear())、點選物件、輸入日期字串(driver.find_element.send_keys(...)) - 時間、起、迄路線、匝道,全都以序號進行選擇(
Select.select_by_index) button鍵實在不知道如何標定,經爬文了解,可以用By.XPATH來點選並點擊。- 將計算結果下載到本機上(檔案大小約1.2M),再開啟使用bs4來解析
- 只需要預測的行車時間。網頁提供7筆讓用路人選擇,包括前2個時段(以半小時為預測時段)以及後4個時段。
主程式
firefox之驅動
driver = webdriver.Firefox(executable_path="/usr/bin/geckodriver")
driver.get("https://1968.freeway.gov.tw/tp_future")
注意事項
- 如果是遠端工作站,需要讓firefox能夠呈現畫面的DISPLAY設定,如mobaxterm的X-Window,且本地電腦必須保持不關機。
- 如果是在一般PC上,也必須保持不關機。
停等的爬蟲
- 這裡因為副程式使用了
Select.select_by_index,按照序號選擇,雖然程式較為簡潔,但是後續還是需要另外建立對照關係,以連結到實際的世界。 - 停等的必要性,需要特別說明一下。
- 若不停等,網頁在輸出成果、更新畫面之前或同時,程式可能就會往下走,造成讀不到結果的情況。
- 如沒有停等、短時間內大量流量,網站管理者會認為是駭客攻擊,而將本地網址列入黑名單被防火牆遮蔽住。經測試,至少要經過1小時,防火牆才會慢慢打開。
- 程式設計了3種的停等
- 副程式內之停等:當2站差距較大時,遠端系統需要一些時間計算出報表,此處停等5秒鐘。(
if abs(s1-s2) >10:time.sleep(5)) - 相鄰2匝道計算之間,停等1秒鐘(
time.sleep(1))。 - 迴圈之間,4~30秒之間取隨機值停等(
time.sleep(np.random.randint(low=5,high=30)))。以規避對方防火牆的分析。
- 副程式內之停等:當2站差距較大時,遠端系統需要一些時間計算出報表,此處停等5秒鐘。(
迴圈下載
SegOfWay={1:84,2:12,3:7,4:84,5:4,6:8,7:7,8:8,9:6,10:8}
#'1_0': '國道1號', 'N1H_0': '國1高架', '2_0': '國道2號',
# '3_0': '國道3號', 'N3A_0': '國道3甲', '4_0': '國道4號',
# '5_0': '國道5號', '6_0': '國道6號', '8_0': '國道8號', '10_0': '國道10號',
col=['date','hr','highway','segment1','segment2']
col+=['t'+str(i) for i in range(1,8)]
df=DataFrame({i:[] for i in col})
d0=DataFrame({i:[0] for i in col})
d0.set_index('date').to_csv('tp_future.csv')
i=0
for d in range(1,10):
for t in range(1,50,7):
for w in range(1,11):
for s1 in range(SegOfWay[w]-1):
s2=s1+1
lags=click_run_save(d,t,w,s1,s2)
df.loc[i,'date']=d
df.iloc[i,1:]=[t,w,s1,s2]+lags
d0.iloc[0,:]=[d,t,w,s1,s2]+lags
i+=1
d0.set_index('date').to_csv('tp_future.csv',header=None,mode='a')
time.sleep(1)
lags=click_run_save(d,t,w,s2,s1)
df.loc[i,'date']=d
df.iloc[i,1:]=[t,w,s2,s1]+lags
d0.iloc[0,:]=[d,t,w,s2,s1]+lags
i+=1
d0.set_index('date').to_csv('tp_future.csv',header=None,mode='a')
time.sleep(np.random.randint(low=5,high=30))
結果之儲存
- 網路可能因為各種原因造成斷線而無法下載,完整下載後再進行儲存,似乎不切實際。
- 此處使用
pandas.DataFrame.to_csv函數中append功能,將每次最內迴圈結束後就將結果儲存起來。 - 由於每次
append都會出現表頭,此處先寫一空白行,正式寫入時再取消輸出表頭即可。
d0.set_index('date').to_csv('tp_future.csv')
...
d0.set_index('date').to_csv('tp_future.csv',header=None,mode='a')
後處理與結果分析
維度的考量
由於車行時間之預報結果共有6個維度(日期、小時、路線、起點、迄點、方向)太過複雜,檢討如下:
- 起、迄點雖然具有空間的解析度的意義,但因
- 起、迄匝道如果太近,車行時間又以分鐘計,有效位數不足,需要長一點的距離。
- TEDS本身的解析度3公里,且具有空間的變化,現在缺的是未來的時間變化。
- 因這兩個維度太長(228個匝道,國1、國3也有84~85個匝道,2個維度張開動輒上千),會消耗太多下載的時間,未及時在模式開始執行前完成,失去預報的意義。
- 經考量,將此2個維度取消,以路線端點之總車行時間予以均化。
- 方向:由於高速公路車流具有顯著的方向性(晨昏小時、放收假日期的車流會相反),然而在模式模擬中並不會呈現,因此還是需要下載,但下載後須先將其平均。
colv='t1 t2 t3 t4 t5 t6 t7'.split()
coli='date hr highway'.split()
ave=pivot_table(df0,index=coli,values=colv,aggfunc=np.mean).reset_index()
字串解讀
- 預報結果的行車時間是字串(如4小時32分、02分),需統一將其轉成整數分鐘,以利平均值之計算。
- 作法分成2段,有小時者先處理,避免先處理分鐘會損壞規則
for c in ["t"+str(i) for i in range(1,8)]:
idx=df.loc[df[c].map(lambda t: '小時' in t)].index
ll=[int(s.split('小時')[0])*60+int(s[-3:-1]) for s in df.loc[idx,c]]
df.loc[idx,c]=ll
for c in ["t"+str(i) for i in range(1,8)]:
idx=df.loc[df[c].map(lambda t: '分' in str(t))].index
ll=[int(s.split('分')[0]) for s in df.loc[idx,c]]
df.loc[idx,c]=ll
陣列轉置
- 由於網站一次預報出7個出發時間的結果,這點可以減省小時迴圈的次數,但結果需要轉置。
- 轉置的作法參考環保署測站數據鄉鎮區平均值之計算的外積(cross product)的作法,將座標軸向量予以外積連乘3次,以取得資料表的引數欄位(
coli)。 - 3個維度向量之宣告
dates=np.arange(1,11) #未來10天
hrs=np.arange(1,50) #每半小時一個預報,1天有49筆(第49筆重複)
hws=np.arange(1,11) #10條路線 國1,高架,國2,國3,國3甲,國4,國5,國6,國8,國10
one=np.ones(shape=(49*10),dtype=int) #單位向量
one1=np.ones(shape=(10),dtype=int) #單位向量
- 3個引數欄位之張量與資料表
dd=np.outer(dates,one).flatten()
h1=np.outer(one1,hrs).flatten()
hh=np.outer(h1,one1).flatten()
ww=np.outer(one,hws).flatten()
df=DataFrame({'date':dd,"hr":hh,"highway":ww})
- 引數欄位完成後,將橫向的7個欄位(
colv)依序填入空格中
df['mins']=0
for h in range(1,50,7):
idx=a.loc[a.hr==h].index
for i in range(7):
t=h+i
c='t'+str(i+1)
df.loc[df.hr==t,'mins']=list(a.loc[idx,c])
使用powerBI進行分析
多維度動態圖形檢視乃powerBI強項(參教學課程:將維度模型轉變為令人驚豔的 Power BI Desktop 報表)
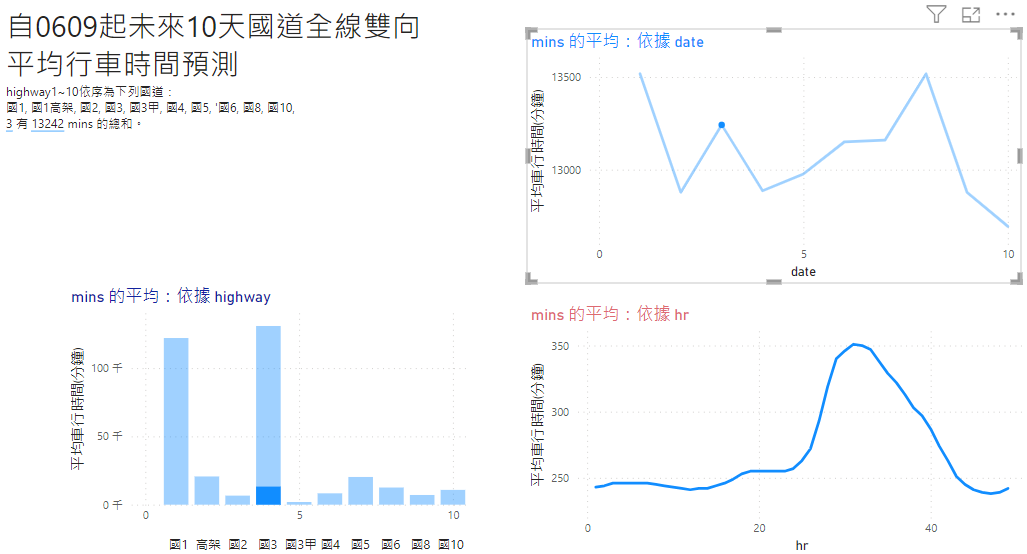
總體來說,國1國3因為距離較長,全路線有最長的行車時間,其次則為國5與五楊高架。就日期來說,6/15(星期四)預測會有較長行車時間,原因未明。而小時變化則顯示明顯的昏峰。
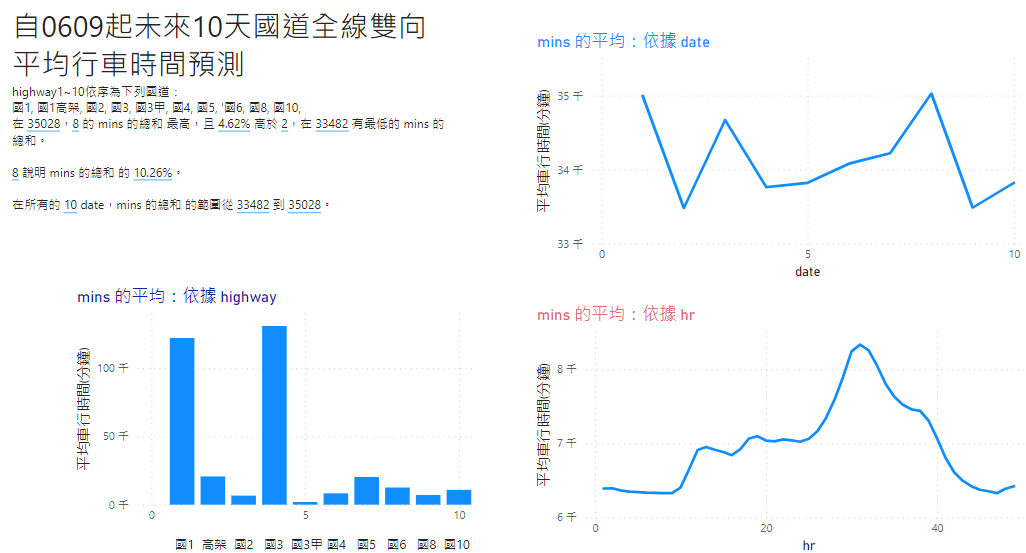
國1工作日(周一):有顯著的晨峰上班車潮
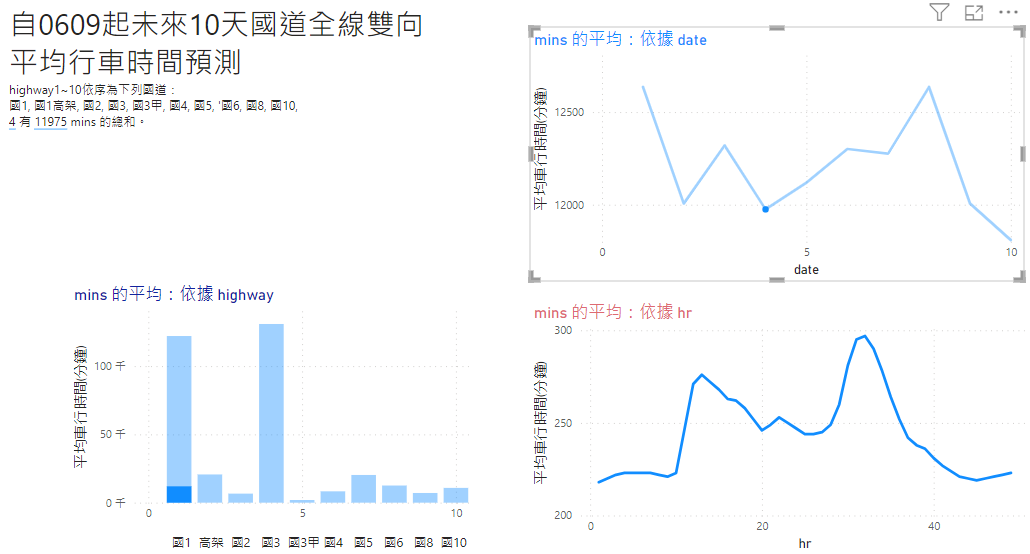
周末現象:國3、國5、國6等具有顯著的周日車潮,特別是在昏峰。此預測符合現實。
程式下載
Download: 高公局車行時間預測數據之批次下載tp_future.py