由CWB數據計算軌跡
背景
空間尺度之界定
逆(反)軌跡圖是空氣污染來源追蹤、溯源解析過程中經常使用的圖像工具。按照污染源與受體空氣品質關係的遠近,分析的尺度有:
- 近距離、~10公里範圍,高斯煙流擴散模式可以應用之範圍,時間約在小時解析度範圍。可以用代表性地面測站之風向直接進行(統計)解析研判。
- 城市~地區尺度,中距離約數10~百公里範圍,受海陸風影響的平坦~平緩地區,時間範圍約在1日~3日之間。可以用地面站網、氣象模式進行解析。
- 地區~長程傳輸現象,約數百~7千公里範圍,除前述現象外,也受到天氣現象的顯著影響,時間範圍約3日~週之間。須以氣象模式、HYSPLIT等模式進行三維風場與軌跡解析。 此處要處理的是城市~地區尺度,因此需應用全臺自動站的風速風向數據。
軌跡正確性與風場模式
軌跡正確性的關鍵在於風場,因此有以:
- 高解析度觀測站數據內插、由於風場的正確性與測站所函蓋的範圍有關,密度較高的平地範圍,會有較高的正確性,而在海上或山區等測站密度較低範圍,可能有較低的正確性。
- 數值氣象預報模式產品、如WRF,有解析度與範圍的限制。一般WRF最高解析度為3公里
- 客觀分析等不同方式產生風場。(介於前2者之間)
策略方案
- CODiS提供的數據至少有300個測站是有風速、風向數據
- 全台面積36,193平方公里,平均一站分攤119平方公里,約為11公里X11公里之解析度,平地還有更高的密度
- 用以內插建立風場,應有其充分性與正確性
- CWB提供有WRF_3KM預報風場,亦足以代表海上、山區等測站較少範圍
- 建立內插方法
- 有測站範圍地區則以測站值為主
- 海上則以模式分析結果,做為3公里X3公里之虛擬測站,納入相同機制進行計算。
- 全區風場計算儲存的必要性
- 全區風場事先計算儲存看似方便,然佔用空間龐大,因電腦速度提高了,因此在實際計算時似乎也沒有提高太多效率。
- 主要由於軌跡線經過網格數有限,實在沒有必要進行全臺風場之計算或儲存。
- 發展路徑
內插程式說明
軌跡程式說明
- 軌跡程式碼可以由githup下載,此處分段說明如下
- 引用模組
1 #!/opt/anaconda3/envs/py27/bin/python
2 import numpy as np
3 from pandas import *
4 import os, sys, subprocess, time, json
5 from scipy.io import FortranFile
6 from datetime import datetime, timedelta
7 import twd97
8 from pyproj import Proj
9
- 讀取引數的副程式
-t測站名稱,可以是環保署測站(單站)、經緯度組合、twd97座標組合,組合以逗號,區隔。-d年月日時共10碼-b是否是反軌跡(True or False)
10 def getarg():
11 """ read time period and station name from argument(std input)
12 traj2kml.py -t daliao -d 2017123101 """
13 import argparse
14 ap = argparse.ArgumentParser()
15 ap.add_argument("-t", "--STNAM", required=True, type=str, help="station name(num),sep by ';' ,or Lat,Lon")
16 ap.add_argument("-d", "--DATE", required=True, type=str, help="yyyymmddhh")
17 ap.add_argument("-b", "--BACK", required=True, type=str, help="True or False")
18 args = vars(ap.parse_args())
19 return [args['STNAM'], args['DATE'],args['BACK']]
20
- 解析引數中的判別(布林值),使用者可以輸入任何大小寫的
yes,true,t,y,1等等。
21 def str2bool(v):
22 if isinstance(v, bool):
23 return v
24 if v.lower() in ('yes', 'true', 't', 'y', '1'):
25 return True
26 elif v.lower() in ('no', 'false', 'f', 'n', '0'):
27 return False
28 else:
29 raise argparse.ArgumentTypeError('Boolean value expected.')
30
- 讀取環保署空品測站站名與編號對照表
31 def nstnam():
32 import json
33 fn = open(path+'sta_list.json')
34 d_nstnam = json.load(fn)
35 d_namnst = {v: k for k, v in d_nstnam.items()}
36 return (d_nstnam, d_namnst)
37
38
- 由風速、風向計算U、V值
39 def ws_uv(ws, wd):
40 PAI = np.pi
41 RAD = (270. - wd) * PAI / 180.0
42 u = ws * np.cos(RAD)
43 v = ws * np.sin(RAD)
44 return u, v
45
46
- 判斷軌跡點是否超出範圍界線
47 def beyond(xpp, ypp):
48 xp_km, yp_km = int(xpp // 1000), int(ypp // 1000)
49 boo = not ((xp_km - x_mesh[0]) * (xp_km - x_mesh[-1]) < 0 and (yp_km - y_mesh[0]) * (yp_km - y_mesh[-1]) < 0)
50 return [boo, (xp_km, yp_km)]
51
52
- 開啟CODiS全台自動氣象站數據檔。事先下載儲存在年代目錄下。
53 def opendf(pdate):
54 ymd = pdate.strftime('%Y%m%d')
55 fname= path+'../' + ymd[:4] + '/cwb' + ymd + '.csv'
56 if not os.path.isfile(fname):
57 dfT=DataFrame({})
58 print ('no file for '+fname)
59 else:
60 try:
61 dfT = read_csv(fname)
62 dfT['stno'] = [i[:6] for i in dfT.stno_name]
63 dfT = dfT.loc[dfT.stno.map(lambda x: x in stno)].reset_index(drop=True)
64 # (dfT.WS>0)&
65 dfT = dfT.fillna(0)
66 ws, wd = np.array(dfT.WS), np.array(dfT.WD)
67 uv = np.array([ws_uv(i, j) for i, j in zip(ws, wd)])
68 dfT['u'], dfT['v'] = (uv[:, i] for i in [0, 1])
69 dfT.ObsTime = [int(i)-1 for i in dfT.ObsTime]
70 except:
71 dfT=DataFrame({})
72 return dfT, ymd
73
- 計算u,v之加權平均值
74 def uvb(r,u,v):
75 dfuv=DataFrame({'R':r,'u':u,'v':v})
76 dfuv=dfuv.sort_values('R',ascending=False).reset_index(drop=True)
77 rr,uu,vv=np.array(dfuv.R)[:ns3],np.array(dfuv.u)[:ns3],np.array(dfuv.v)[:ns3]
78 rr=rr/sum(rr)
79 ub,vb=sum(rr*uu),sum(rr*vv)
80 return ub,vb
81
82
- 主程式
- 設定
Proj座標轉換工具pnyc。因本次使用CODiS數據,還是以臺灣本島為主,因此主要還是使用twd97系統。 - 設定網格數及測站數
nx,ny,ns - 讀取權重計算結果
- 讀取環保署空品測站站名與編號對照表
- 讀取並解析引數中的布林(
BACK)與日期(DATE),並計算起訖時間(bdate,next_date)。 - 解析(
nam)站名
- 設定
83 path='/Users/Data/cwb/e-service/surf_trj/'
84
85 Latitude_Pole, Longitude_Pole = 23.61000, 120.9900
86 Xcent, Ycent = twd97.fromwgs84(Latitude_Pole, Longitude_Pole)
87 pnyc = Proj(proj='lcc', datum='NAD83', lat_1=10, lat_2=40,
88 lat_0=Latitude_Pole, lon_0=Longitude_Pole, x_0=0, y_0=0.0)
89
90
91 # restore the matrix
92 nx, ny, ns = 252, 414, 431
93 fnameO = path+'R%d_%d_%d.bin' % (ny, nx, ns)
94 with FortranFile(fnameO, 'r') as f:
95 R2 = f.read_record(dtype=np.float64)
96 R2 = R2.reshape(ny, nx, ns)
97 with FortranFile(path+'x_mesh.bin', 'r') as f:
98 x_mesh = list(f.read_record(dtype=np.int64))
99 with FortranFile(path+'y_mesh.bin', 'r') as f:
100 y_mesh = list(f.read_record(dtype=np.int64))
101
102 (d_nstnam, d_namnst) = nstnam()
103 stnam, DATE, BACK = getarg()
104 BACK=str2bool(BACK)
105 BF=-1
106 if not BACK:BF=1
107 bdate = datetime(int(DATE[:4]), int(DATE[4:6]), int(DATE[6:8]), int(DATE[8:]))
108 next_date= bdate + timedelta(hours=96*BF)
109 nam = [i for i in stnam.split(';')]
- 解析軌跡起始點(twd97系統)
- 測站名稱可以是環保署測站、經緯度組合、twd97座標組合
- 環保署測站:由
sta_ll.csv中讀取位置 - 經緯度組合:順序為(維度,經度),
- twd97座標組合:直接使用
110 if len(nam) > 1:
111 try:
112 lat = float(nam[0])
113 lon = float(nam[1])
114 except:
115 sys.exit('more than two station, suggest executing iteratively')
116 else:
117 # in case of lat,lon
118 if lat < 90.:
119 xy0 = twd97.fromwgs84(lat,lon)
120 x0, y0 =([xy0[i]] for i in [0,1])
121 nam[0] = str(round(lat,2))+'_'+str(round(lon,2))+'_'
122 # in case of twd97_x,y
123 else:
124 # test the coordinate unit
125 if lat>1000.:
126 x0, y0 = [lat],[lon]
127 nam[0] = str(int(lat/1000))+'+'+str(int(lon/1000))+'_'
128 else:
129 x0, y0 = [lat*1000],[lon*1000]
130 nam[0] = str(int(lat))+'_'+str(int(lon))+'_'
131
132 # len(nam)==1, read the location from csv files
133 else:
134 for stnam in nam:
135 try:
136 nst=[int(stnam)]
137 except:
138 astnam=stnam
139 if astnam not in d_namnst: sys.exit("station name not right: " + stnam)
140 nst = [int(d_namnst[i]) for i in nam]
141 else:
142 if stnam not in d_nstnam: sys.exit("station number not right: " + stnam)
143 nam[0]=d_nstnam[stnam]
144 # locations of air quality stations
145 # read from the EPA web.sprx
146 fname = path+'sta_ll.csv'
147 sta_list = read_csv(fname)
148 x0, y0 = [], []
149 for s in nst:
150 sta1 = sta_list.loc[sta_list.ID == s].reset_index(drop=True)
151 xx,yy=pnyc(list(sta1['lon'])[0],list(sta1['lat'])[0], inverse=False)
152 print xx,yy
153 x0.append(xx+Xcent) #list(sta1['twd_x'])[0]-Xcent)
154 y0.append(yy+Ycent) #list(sta1['twd_y'])[0]-Ycent)
155
- 軌跡計算初始化
- 讀取CODiS測站位置
stat_wnd.csv - 軌跡點間距時間
delt:15秒 - 讀取當日CODiS測站數據
opendf(pdate)
- 讀取CODiS測站位置
156 xp, yp = x0, y0
157 dfS = read_csv(path+'stat_wnd.csv')
158 if len(dfS) != ns: sys.exit('ns not right')
159 stno = list(dfS.stno)
160 pdate = bdate
161 df, ymd0 = opendf(pdate)
162 if len(df)==0:sys.exit('no cwb data for date of:'+ymd0)
163 delt = 15
164 s = 0
165 o_ymdh,o_time,o_xp,o_yp,l_xp,l_yp=[],[],[],[],[],[]
166 itime=0
167 ymdh=int(DATE)
168 o_ymdh.append(nam[0]+'@'+pdate.strftime('%Y/%m/%d/%H:00'))
169 o_time.append('hour='+str(itime))
170 o_xp.append(xp[s])
171 o_yp.append(yp[s])
172 l_xp.append(xp[s])
173 l_yp.append(yp[s])
174 ns3=int(ns)
- 開始計算軌跡點,知道超出範圍界線
- 由
df中篩出個別小時數據,另存成df1,如有缺漏,則補以0。 - 由
df1中提取u,v
- 由
175 while not beyond(xp[s], yp[s])[0] and len(df)!=0:
176 boo=pdate>next_date
177 if not BACK:boo=pdate<next_date
178 if not boo:break
179 df1 = df.loc[(df.ObsTime == ymdh) & (df.stno.map(lambda x:x in stno))].reset_index(drop=True)
180 df1 = df1.drop_duplicates()
181 ldf1=len(df1)
182 if ldf1 < ns:
183 if boo:
184 ns2 = set(df1.stno)
185 miss = set(stno) - set(ns2)
186 if len(miss)!=0:
187 for m in miss:
188 df2= DataFrame({'stno_name':[m],'ObsTime':[ymdh]})
189 df1=df1.append(df2,ignore_index=True, sort=False)
190 else:
191 print 'df1 not right' + str(ymdh)
192 break
193 df1=df1.sort_values('stno_name').reset_index(drop=True)
194 df1 = df1.fillna(0)
195 u, v = np.array(df1.u), np.array(list(df1.v))
- 執行該小時軌跡點的計算
- 由位置找到加權
R2[iy, ix, :] - 進行內插
ub, vb = uvb(R2[iy, ix, :],u,v) - 計算下一點
xp[s], yp[s] = xp[s]+BF*delt * ub, yp[s]+BF*delt * vb - 儲存結果
- 由位置找到加權
196 for sec in range(0, 3601, delt):
197 boo, (xp_km, yp_km) = beyond(xp[s], yp[s])
198 if boo: break
199 ix, iy = x_mesh.index(xp_km), y_mesh.index(yp_km)
200 if sec == 0:
201 ix0, iy0 = ix, iy
202 ub, vb = uvb(R2[iy, ix, :],u,v)
203 else:
204 if ix0 != ix or iy0 != iy:
205 # ub, vb = sum(R2[iy, ix, :] * u), sum(R2[iy, ix, :] * v)
206 ub, vb = uvb(R2[iy, ix, :],u,v)
207 ix0, iy0 = ix, iy
208 xp[s], yp[s] = xp[s]+BF*delt * ub, yp[s]+BF*delt * vb
209 l_xp.append(xp[s])
210 l_yp.append(yp[s])
211 pdate = pdate + timedelta(hours=BF)
212 ymdh = int(pdate.strftime('%Y%m%d%H'))
213 itime+=1
214 o_ymdh.append(pdate.strftime('%Y/%m/%d/%H:00'))
215 o_time.append('hour='+str(itime))
216 o_xp.append(xp[s])
217 o_yp.append(yp[s])
218 if pdate.strftime('%Y%m%d') != ymd0:
219 df, ymd0 = opendf(pdate)
220 if len(df)==0:break
- 儲存逐時軌跡點檔案(
twd97座標值)
221 print('beyond:',beyond(xp[s], yp[s])[0],'len(df)=',len(df))
222 df=DataFrame({'ymdh':o_ymdh,'xp':o_xp,'yp':o_yp,'Hour':o_time})
223 col=['xp','yp','Hour','ymdh']
224 dr='b'
225 if BF!=-1:dr='f'
226 name='trj_results/'+dr+'trj'+nam[0]+DATE+'.csv'
227 df[col].set_index('xp').to_csv(name)
- 計算並寫出經緯度值、寫出測站名稱
228 #geodetic LL
229 x,y=np.array(o_xp)-Xcent,np.array(o_yp)-Ycent
230 lon, lat = pnyc(x, y, inverse=True)
231 dfg=DataFrame({'lon':lon,'lat':lat})
232 dfg.set_index('lon').to_csv(name.replace('.csv','_mark.csv'),header=None)
233 with open('trj_results/filename.txt','w') as f:
234 f.write(name.split('/')[1])
235
- 儲存逐點結果
236 # output the line segments for each delta_t
237 dfL=DataFrame({'TWD97_x':l_xp,'TWD97_y':l_yp})
238 dfL.set_index('TWD97_x').to_csv(name.replace('.csv','L.csv'))
239 #geodetic LL
240 x,y=np.array(l_xp)-Xcent,np.array(l_yp)-Ycent
241 lon, lat = pnyc(x, y, inverse=True)
242 dfg=DataFrame({'lon':lon,'lat':lat})
243 dfg.set_index('lon').to_csv(name.replace('.csv','_line.csv'),header=None)
244
- 呼叫外部程式轉換成KML檔案及bln檔(for
SURFER)- csv2kml.py
- KML是Google地圖、Open Street Map等地圖系統相容的檔案格式
245 #make kml file
246 dir='NC'
247 if not BACK:dir='RC'
248 os.system('/opt/local/bin/csv2kml.py -f '+name+' -n '+dir+' -g TWD97')
249 os.system('/opt/local/bin/csv2bln.cs '+name)
csv2bln
- csv2bln.cs為下列腳本。
echo $(( $(wc -l $1|/opt/local/bin/awkk 1) - 1 )) > $1.bln
sed 1d $1 >> $1.bln
alias awkk=awk '{print $'$1'}'
成果檢討
- 2018/10/27 12時林園vs當天2時北高雄某廠燃燒塔之正軌跡(紅色)及林園測站反軌跡(白色)
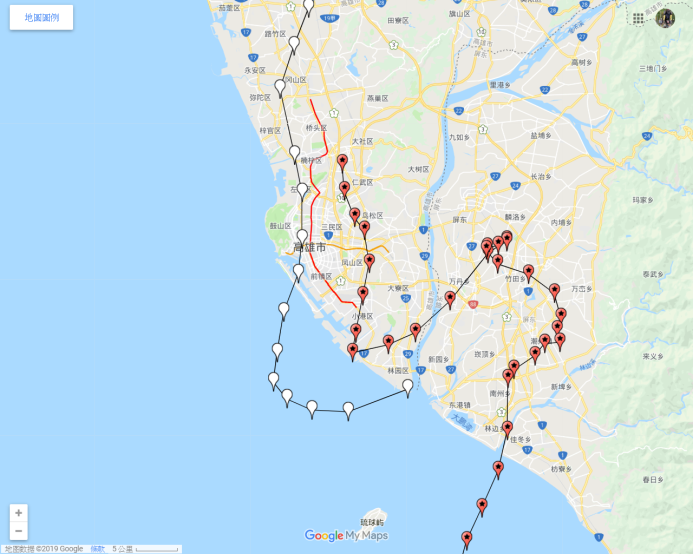
- 燃燒塔正軌跡分析證實了以北高雄燃燒塔對反應生成測站O3高值有較大的可能性,此處分析其他事件的情況,並將測站O3尖峰時間的反軌跡繪出以進行比較驗證。
- 圖中白色點線為林園測站O3尖峰時間之逆軌跡,
- 北方工業區燃燒塔以當天凌晨CEMS記錄最大流量發生時間,做為之正軌跡線的起始時間,圖中為紅色點線表示。
- 由圖中可以發現,紅、白2條軌跡線在高雄市西南側沿海與近海地區大多呈現平行運動,間距約為2~4公里,約為一般網格模式解析度範圍,應為污染源的精確位置、或風場模式內插所造成的誤差。
- 然而就污染物受日夜海陸風的性質而言,圖中正、反軌跡線可以確認造成林園測站O3高值的污染源,非常可能就是仁大工業區之燃燒塔排放。
程式原始碼
可以在github找到:
python程式
Download: traj2kml.py
Reference
- MM5/WRF之little_r格式
- NOAA, HYSPLIT
- Jimy Dudhia, WRF Four Dimensional Data Assimilation (FDDA), documen.site, May 12, 2018
- Tom.Chen, Python converter between TWD97 and WGS84, pypi.org, Oct 22, 2014
- Wiki, Keyhole Markup Language, wikipedia.org,last edited on 24 October 2021