CODiS日報表下載整併
背景
- 中央氣象局每天公開其地面自動站觀測結果在CODiS(CWB Observation Data Inquire System)網站,項目齊備、測站密度非常高、時間可以追溯到1995年,是非常完整的資料庫。
- 其數據過去曾應用在風場的產生、反軌跡之追蹤、以及轉成MM5/WRF之little_r格式,以備應用在WRF模式的4階同化模擬,等等作業化系統,
- 由於整併後以全日所有測站同一檔案儲存,具備更高的可用性。
- 此處介紹台灣地區中央氣象局自動站數據之內容、下載作業方式、以及爬蟲程式設計之細節。
網址及畫面
- 網址:https://e-service.cwb.gov.tw/HistoryDataQuery/
- 操作方式
- 由下拉選單選取縣市、測站,或由圖面直接點選WMO標準地面測站
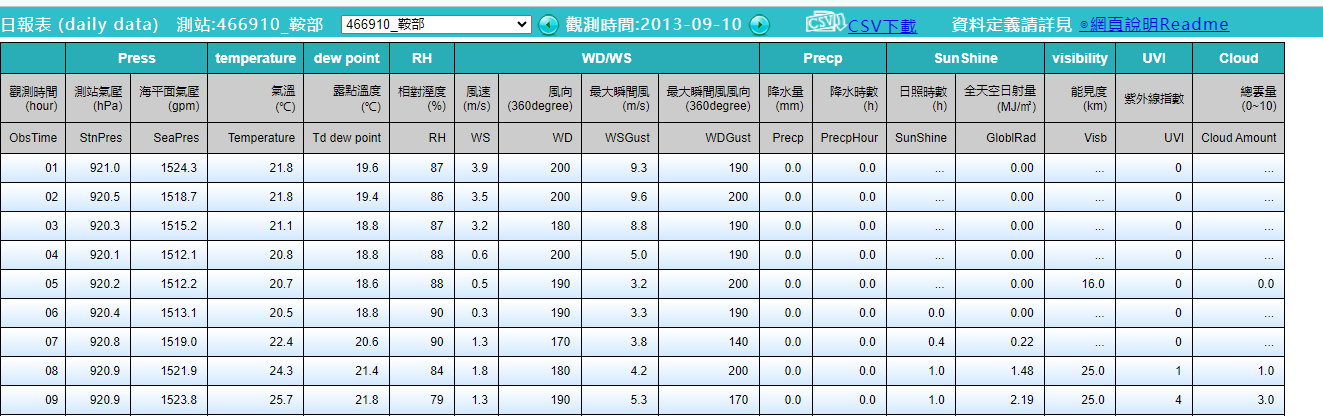
- 資料格式:有日報、月報、及年報。日報表為逐時值,為此處下載的對象
- 時間:由月曆中點選、或直接鍵入時間(必須是YYYY-MM-DD形式)
- 按下「查詢」後即能得到一張該站的逐時表格
- 按下「CSV下載」即能將表格另存成csv檔案
- 畫面
CODiS數據目前作業情況
- 更新頻率時間:每日12(L)時更新,更新至前一日24時(落後實際時間12小時)。
- 日報(總)表之內容
- 以每站報表格式,記錄前一日24小時觀測數據
- 格式:為csv格式
- 表頭項目(按順序):
- 站名、觀測時間、
- 壓力(測站氣壓、海面氣壓)、
- 溫濕(溫度、濕球溫度、相對濕度)、
- 風(風速、風向、風速擾動、風向擾動)、
- 雲雨日(降雨、日照、幅射、能見度、UVI、雲量)等等數據。
- 檔案範例
stno_name,ObsTime,StnPres,SeaPres,Temperature,Td dew point,RH,WS,WD,WSGust,WDGust,Precp,PrecpHour,SunShine,GloblRad,Visb,UVI,Cloud Amount
466880_板橋,2020061901.0,1006.1,1007.3,27.7,24.6,83.0,1.1,200.0,3.0,190.0,0.0,0.0,,0.00,,,
466880_板橋,2020061902.0,1006.0,1007.2,27.6,24.9,85.0,1.1,210.0,3.3,190.0,0.0,0.0,,0.00,20.0,,2.0
466880_板橋,2020061903.0,1006.2,1007.4,26.9,24.6,87.0,1.4,200.0,3.8,190.0,0.0,0.0,,0.00,,,
466880_板橋,2020061904.0,1006.3,1007.5,26.8,24.5,87.0,0.8,210.0,2.2,180.0,0.0,0.0,,0.00,,,
466880_板橋,2020061905.0,1006.2,1007.4,26.7,24.3,87.0,0.6,210.0,2.8,210.0,0.0,0.0,,0.00,20.0,,4.0
466880_板橋,2020061906.0,1006.6,1007.8,26.9,23.3,81.0,1.0,190.0,2.9,240.0,0.0,0.0,0.2,0.06,,,
466880_板橋,2020061907.0,1007.0,1008.2,29.7,22.4,65.0,2.1,200.0,4.8,190.0,0.0,0.0,1.0,0.73,,,
466880_板橋,2020061908.0,1007.2,1008.4,30.6,21.4,58.0,2.8,230.0,7.2,210.0,0.0,0.0,1.0,1.11,30.0,,8.0
466880_板橋,2020061909.0,1007.2,1008.4,31.6,21.5,55.0,3.1,220.0,7.5,200.0,0.0,0.0,1.0,1.32,30.0,,8.0
...
解決方案
現行既有方案
- 年度數據之購置
- 傳統作法,數據約落後實際觀測時間至少10日
- 數據是以分站儲存,單站檔案為全年逐時之ASCII碼,購入數據後仍然需要整理、消化後方能應用。
- 一般以購置局屬地面氣象站(有人站)為主,如要購買所有自動站所費不貲。
- 網友鄭文吉自行維護之中央氣象局自動氣象站觀測資料彙整網頁服務
- 數據來源:中央氣象局氣象資料開放平台、逐時下載
- 分站提供最新(落後實際時間約3~4小時)之觀測數據
- 也按照地區、月份、測站種類整理中央氣象局自動氣象站觀測資料,提供歷史檔。
- Tien Yang及Allen Chou公開其2014~2018年的爬蟲專案,也是用
BeutifulSoup來做,將所要下載的測站、年代直接改在程式碼中進行下載。 - muse648這2篇網誌有完整
bs批次下載的應用範例,是用request.get方式取得內容。不過因為不是氣象方面的專業,並沒有仔細處理缺漏值各項註記,程式執行應該會遭遇困難。不然就是僅儲存字串,這也不失為一個簡捷的方案。
方案考量
- leading time
- 國內外氣象中心主要數據更新頻率皆以日為單位,如非以災害應變為目標,似無需太過密集執行。
- 對於空窗時間之氣象數據:仍有數值預報結果可供參考,不致造成數據空窗。
- 資料結構
- 單站數據實在很難應用,應還是以綜整全臺數據為目標
爬蟲程式
作業方式
- 原始碼公開於github
- 需要外部檔案stats_tab.csv為測站位置座標等內容輸出檔案
- 執行批次:執行date指令以驅動python程式,詳get_cwb.sh
- 自動執行排程:每天中午執行
grep cwb /etc/crontab
0 12 * * * kuang /home/backup/data/cwb/e-service/get_cwb.sh >& /home/backup/data/cwb/e-service/get_cwb.out
程式說明
- 此處為早期發展的python程式,仍為py27版本。會影響後續中文內容的讀取(如stn_dotCWB)。
- 輸入模組:包括pandas與bs4
1 #!/opt/anaconda3/envs/py27/bin/python
2 #coding='utf8'
3 from pandas import *
4 from bs4 import BeautifulSoup
5 import os,sys, subprocess, time
6
7
- 副程式:取得引數、判斷日期的正確性
8 def getarg():
9 """ read time period and station name from argument(std input)
10 rd_cwbDay.py -d 2017-12-31 """
11 import argparse
12 ap = argparse.ArgumentParser()
13 ap.add_argument("-d", "--DATE", required=True, type=str, help="yyyy-mm-dd")
14 args = vars(ap.parse_args())
15 return args['DATE']
16
17 def is_date_valid(date):
18 # this_date = '%d/%d/%d' % (month, day, year)
19 try:
20 time.strptime(date, '%Y-%m-%d')
21 except ValueError:
22 return False
23 else:
24 return True
25
- 取得引數、判斷正確性、預先開啟結果檔(避免覆蓋)
26 date = getarg()
27 if not is_date_valid(date):sys.exit('not invalid:'+date)
28 ymd = int(date.replace('-', ''))
29 dir = '/Users/Data/cwb/e-service/read_web/'
30 dir1 = dir + '../' + date[:4] + '/'
31 fnameO=dir1 + 'cwb' + str(ymd) + '.csv'
32 #if os.path.isfile(fnameO):sys.exit('file_exit:'+date)
33 #touch and open for keeping from writing by others
34 os.system('touch '+fnameO)
35 ftext=open(fnameO,'w')
36
- 程式基本設定
- 異常標籤
mal之定義 - 輸入測站位置stats_tab.csv
cgi指令之文字片段- 隨機休息之設計
- 早期氣象局網站設定了防火牆,倘若程式太過密集讀取網站,會被視為駭客攻擊而被拒絕,因此2次讀取中間需要有不同(隨機)長度的休息,此處設計程式日間執行會有較小的間距,
- 日間定義:8~18點
- 後來氣象局調整了管制政策,因此相關程式碼不必再作用
- 異常標籤
37 #batcmd="date +%H"
38 #ymdh = int(subprocess.check_output(batcmd, shell=True)[:-1])
39 #dayt=0
40 #if ymdh<19 and ymdh>=8:dayt=10
41 mal = ['T', 'V', '/', 'X','&']
42 dfS = read_csv(dir + 'stats_tab.csv')
43 h0 = 'https://e-service.cwb.gov.tw/HistoryDataQuery/'
44 h1 = 'DayDataController.do\?command=viewMain\&station\='
45 h2 = '\&stname\='
46 h3 = '\&datepicker\='
47
- 開始讀取
html內容- 按照測站順序進行
- 下載測站
url成為本地固定檔名cwbDay.html- 因url有中文字,需要轉成%25格式,乃參考網友的建議,使用下列程式進行轉換,存成
url_nam25備用。 - python3 以後的用法:
from urllib.parse import quote
kuang@114-32-164-198 /Users/Data/cwb/e-service/read_web $ cat rd_url25.py from pandas import * import urllib df=read_csv('stats_tab.csv') df['url_nam']=[urllib.quote(i.decode('utf8').encode('utf8')) for i in df.stat_name] df['url_nam25']=[i.replace('%','%25') for i in df.url_nam] df.set_index('stno').to_csv('stats_tab.csv') - 因url有中文字,需要轉成%25格式,乃參考網友的建議,使用下列程式進行轉換,存成
- 取得html檔案並解讀
48 ib = 0
49 for ii in range(ib, len(dfS)):
50 orig = h1 + dfS.loc[ii, 'stno'] + h2 + dfS.loc[ii, 'url_nam25'] + h3 + date
51 print h0 + orig + ' -O cwbDay.html'
52 os.system('curl ' + h0 + orig + ' -o cwbDay.html')
53 fname = 'cwbDay.html'
54 fn = open(fname, 'r')
55 soup = BeautifulSoup(fn, 'html.parser')
56
- 第一個測站:讀取檔頭,並形成新的DataFrame(
df),準備承接測站數據。
57 if ii == ib:
58 col_tr = soup.find_all("tr", class_="third_tr")
59 col_th = col_tr[0].find_all('th')
60 col = ['stno_name'] + \
61 [str(col_th[i]).split('>')[1].split('<')[0] for i in range(len(col_th))]
62 df = DataFrame({i: [] for i in col})
63 df.columns = col
64
- 準備個別測站的空白DataFrame:
dfi- 讀取測站名稱(
stno_name) - 讀取年月日(
ymd)
- 讀取測站名稱(
65 dfi = DataFrame({i: [] for i in col})
66 dfi.columns = col
67 tr = soup.find_all('tr')
68 if len(tr) < 28: continue
69 stno_name = str(tr[0].find_all('td')[1]).split('>')[1].split('<')[0] \
70 .replace('\xc2', '').replace('\xa0', '').split(':')[1]
71 ymd = str(tr[0].find_all('td')[4]).split('>')[1].split('<')[0] \
72 .replace('\xc2', '').replace('\xa0', '').split(':')[1]
73 ymd = int(ymd.replace('-', ''))
- 依序讀取測值
- 異常值之處理
- 形成DataFrame(
dfi)的各欄位序列
74 for i in range(4, len(tr)):
75 a = tr[i].find_all('td')
76 col_val = []
77 for j in range(len(a)):
78 val = str(a[j]).split('>')[1].split('<')[0].replace('\xc2', '').replace('\xa0', '')
79 if len(val) == 0:
80 val = 0.
81 else:
82 if '.' not in val and val not in mal:
83 val = float(val)
84 elif val in mal:
85 val = 0.
86 if val == '...': val = ''
87 col_val.append(val)
88 col_val[0] = int(ymd * 100 + col_val[0])
89 col_val = [stno_name] + col_val
90 dfi.loc[i - 4, :] = col_val
91
- 累積測站DataFrame(
dfi)、存檔
92 if ii == ib:
93 df = dfi
94 else:
95 df = df.append(dfi, ignore_index=True)
96 # sec=str(round(np.random.rand(1)[0]*dayt,2))
97 # os.system('sleep '+sec+'s')
98 # ifname+=1
99 df.stno_name=[i[:6] for i in df.stno_name]
100 os.system('mkdir -p ' + dir1)
101 df.set_index('stno_name').to_csv(ftext)
102 ftext.close()
103 #sec=str(round(np.random.rand(1)[0]*dayt*12,2))
104 #os.system('sleep '+sec+'s')
html之更新
2020/10月底CWB更新了網頁CODiS內容,把第2等級的欄位訊息放在第3等級。
* old
* 56 col_tr = soup.find_all("tr", class_="second_tr")
* 57 col_th = col_tr[1].find_all('th')
* new
* 56 col_tr = soup.find_all("tr", class_="third_tr")
* 57 col_th = col_tr[0].find_all('th')
###
Further Application
Reference
- disscusion on About Convert csv data file format to little_r format WRF & MPAS-A Support Forum, Mon Dec 03, 2018 6:23 am.
- willismax, 10分鐘的Pandas入門, hackmd.io, 2021-03
- Leonard Richardson, Beautiful Soup, crummy, 2020-10-03
- G. T. Wang, Linux 設定 crontab 例行性工作排程教學與範例,gtwang.org, 2019/06/28
- G. T. Wang, Linux 使用wget 指令自動下載網頁檔案教學與範例, gtwang.org, 2017/08/25
- KD Chang, Linux Curl Command 指令與基本操作入門教學, techbridge, 2019-02-01
- Here, 2021-11-26
- Allen Chou, CWB-Observation-Crawler, github, 18 Dec 2018
- TienYang, crawler-central-weather, github,12 Jan 2015
- 臨床統計農莊, python網路爬蟲輕鬆取得氣候資料(1)~(2), blogspot, 8月 29, 2019