km.py程式說明
背景
- 大氣移動的軌跡本身是很紛亂的,要分析多年來、逐時的軌跡線,其結果樣貌也是非常多樣的。不但有季節特性、也有地形效應、局部的日夜垂直運動。
- 過去的分析方式包括
- 機率分析
- 天氣類型分析
- 典型事件分析
- 此處選擇以叢結分析,將空間中的位置組合當成分析對象,進行統計上的客觀分類,以了解軌跡的大致走向。
- 這支程式讀取choose10.py結果,以K-means方法取其代表性叢集。
km.py程式說明
- 要加入分析的軌跡檔案、需要先將檔名列於一文字檔案裡。
- 軌跡線是同步處理的作業,因此需等候所有的計算都結束,再整理檔案名稱。
程式IO
- arguments:
- *10.csv檔案路徑名稱之文字檔(
txt) - nclt: number of clusters
- *10.csv檔案路徑名稱之文字檔(
- 輸入檔
- *10.csv:choose10.py的結果
- tmplateD1_3km.nc:由JI轉換成網格化座標位置
- 輸出檔
- lab.csv:逐時的叢集編號
- ‘res’+str(l)+’.csv’ :各叢集的代表性軌跡
- 內掛後處理(csv2kml.py):
- 由csv產生kml檔案
- 可以google map、leaflet、NCL等套件等等進行繪圖
讀取軌跡點
- 此處將網格位置標籤予以還原。d1_3Km的個數上千個,因此
JI的位數共有8碼。 - 將位置標籤
j值收在trjs的前半段、i值收在後半段 - 如為空檔案,則將其跳過。
- 全為0的陣列將會佔掉一個類別,需特別降其去掉。
trjs=np.zeros(shape=(len(fnames),20))
tex=10000
n,m=0,0
ymdh=[]
for fname in fnames:
try:
df=read_csv(fname+'10.csv')
except:
m=m+1
continue
trjs[n,:10]=[i//tex for i in df.JI3]
trjs[n,10:]=[i%tex for i in df.JI3]
ymdh.append(int(fname[idx:idx+10]))
n+=1
trjs=trjs[:-m,:]
執行kmeans
- 結果標籤存在
lab.csv - 各標籤的代表性軌跡線(
ji矩陣)。依序將其寫出。
clt = KMeans(n_clusters = nclt)
clt.fit(trjs)
a=clt.labels_
dfa=DataFrame({'lab':a,'ymdh':ymdh})
dfa.set_index('lab').to_csv('lab.csv')
ji=np.array(clt.cluster_centers_,dtype=int)
...
for l in range(nclt):
des=['Line'+str(l)+'_'+str(i) for i in range(10)]
df=DataFrame({'TWD97_x':[Xcent+x_mesh[i] for i in ji[l,10:]],'TWD97_y':[Ycent+y_mesh[i] for i in ji[l,:10]],'lab':des,'des':des})
df.set_index('TWD97_x').to_csv('res'+str(l)+'.csv')
後處理
- 除了軌跡線之外,也需要標籤點位。
- 此處0~1 黑色一般點(NL)、2~3 加亮點(HL)、4~則為紅色點(RL)
os.system('for i in {0..'+str(nclt-1)+'};do cp res$i.csv res${i}L.csv;done')
os.system('for i in {4..'+str(nclt-1)+'};do csv2kml.py -f res$i.csv -g TWD97 -n RL;done')
os.system('for i in {2..3};do csv2kml.py -f res$i.csv -g TWD97 -n HL;done')
os.system('for i in {0..1};do csv2kml.py -f res$i.csv -g TWD97 -n NL;done')
叢集數與分析結果
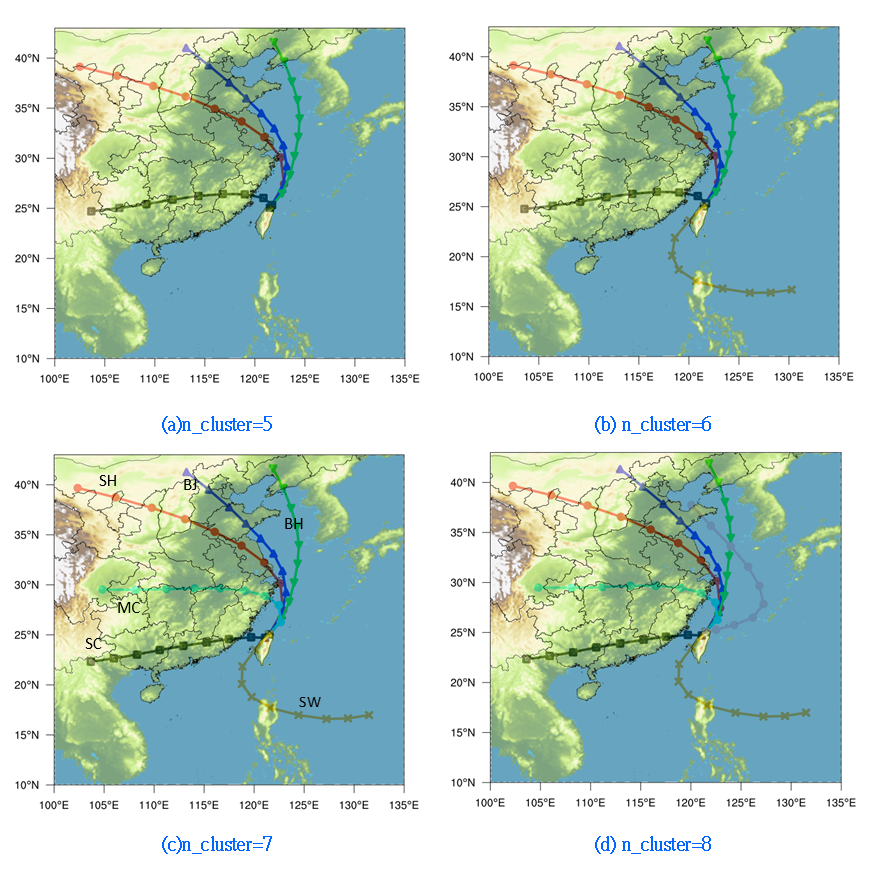 |
|---|
| 叢集數與反軌跡線叢集分析結果 |
程式下載
Download: 軌跡叢集分析前處理程式choose10.py