d01地理分區檔案之準備
背景
withinD1.py程式說明
IO檔案
- 輸入檔
- 大陸行政區邊界線之
kml檔案:doc.kml - 行政區名稱與空氣質量預報區之對照:
chn_admbnda_ocha.csv d01範圍之nc檔模版:PM25_202001-05_d1.nc
- 大陸行政區邊界線之
- 輸出檔
- 多邊形之頂點座標(檢核用):
doc.csv - 原
nc檔模版:改成地理分區編號(1~7),VERDI檢核用 - 地理分區的網格遮罩(gridmask)檔案:
AQFZones_EAsia_81K.nc
- 多邊形之頂點座標(檢核用):
分段說明
1 from pandas import *
2 from pykml import parser
3 from os import path, system
4 import numpy as np
5 import netCDF4
6 import subprocess
7 from pyproj import Proj
8 from shapely.geometry import Point, Polygon
9
- 與rd_kml.py相同之內容
- 記錄多邊形(
Dplg)與名稱(Nplg)等序列備用
- 記錄多邊形(
10 kml_file = path.join('doc.kml')
11 with open(kml_file) as f:
12 doc = parser.parse(f).getroot()
13 plms=doc.findall('.//{http://www.opengis.net/kml/2.2}Placemark')
14 names=[i.name for i in plms]
15
16 mtgs=doc.findall('.//{http://www.opengis.net/kml/2.2}MultiGeometry')
17 mtg_tag=[str(i.xpath).split()[-1][:-2] for i in mtgs]
18
19 plgs=doc.findall('.//{http://www.opengis.net/kml/2.2}Polygon')
20 nplgs=len(plgs)
21 plg_prt=[str(i.getparent().values).split()[-1][:-2] for i in plgs]
22
23 lon,lat,num,nam=[],[],[],[]
24 n=0
25 #store the polygons
26 Dplg=[]
27 #name for the polygons
28 Nplg=[]
29 for plg in plgs:
30 iplg=plgs.index(plg)
31 imtg=mtg_tag.index(plg_prt[iplg])
32 name=names[imtg]
33 Nplg.append(name)
34 coord=plg.findall('.//{http://www.opengis.net/kml/2.2}coordinates')
35 c=coord[0].pyval.split()
36 long=[float(ln.split(',')[0]) for ln in c]
37 lati=[float(ln.split(',')[1]) for ln in c]
38 crd=[(i,j) for i,j in zip(lati,long)]
39 Dplg.append(crd)
40 for ln in c:
41 if n%3==0:
42 lon.append(ln.split(',')[0])
43 lat.append(ln.split(',')[1])
44 num.append('n='+str(n))
45 nam.append(name)
46 n+=1
47 #output the coordinates for checking
48 df=DataFrame({'lon':lon,'lat':lat,'num':num,'nam':nam})
49 df.set_index('lon').to_csv('doc.csv')
50
51
- 由
csv檔讀取名稱及分區對照dist為名稱與編號的對照。雖然只是按順序排列的對照關係,但是字典對照表(dict)會比.index()快很多。
52 #form the dict of name to district from csv file
53 df=read_csv('chn_admbnda_ocha.csv',encoding='big5')
54 nam2dis={i:j for i,j in zip(df.ADM1_EN,df.district)}
55 a=list(set(df.district));a.sort()
56 a=['NA']+a
57 dist={a[i]:i for i in range(len(a))}
58
59 #check the content of names
60 for i in names:
61 if i not in nam2dis:print(i)
62
63 Latitude_Pole, Longitude_Pole = 23.61000, 120.9900
64 pnyc = Proj(proj='lcc', datum='NAD83', lat_1=10, lat_2=40,
65 lat_0=Latitude_Pole, lon_0=Longitude_Pole, x_0=0, y_0=0.0)
66
67 #reading the d1 template
68 fname='PM25_202001-05_d1.nc'
69 nc = netCDF4.Dataset(fname,'r+')
70 v4=list(filter(lambda x:nc.variables[x].ndim==4, [i for i in nc.variables]))
71 nt,nlay,nrow,ncol=(nc.variables[v4[0]].shape[i] for i in range(4))
72 X=[nc.XORIG+nc.XCELL*i for i in range(ncol)]
73 Y=[nc.YORIG+nc.YCELL*i for i in range(nrow)]
74 x_g, y_g = np.meshgrid(X, Y)
75 Plon, Plat= pnyc(x_g,y_g, inverse=True)
76 Plat1d,Plon1d=Plat.flatten(),Plon.flatten()
77 p1d=[Point(Plat1d[i],Plon1d[i]) for i in range(nrow*ncol)]
78
79
- 每個多邊形依序進行
within之判斷,- 全部網格系統的點位依序進行判斷
- 判斷結果轉成2維矩陣,並以
np.where找到布林值為真的位置(idx) - 以批次方式將這些位置之
DIS矩陣給定1~7之分區編號 - 回存編號值後存檔(進行VERDI檢查,詳下)
80 #store the index of districts(1~7) for each grids for VERDI cheking
81 DIS=np.zeros(shape=(nrow,ncol),dtype=int)
82 for n in range(nplgs):
83 poly = Polygon(Dplg[n])
84 a=np.array([i.within(poly) for i in p1d]).reshape(nrow,ncol)
85 idx=np.where(a==True)
86 if len(idx[0])==0:continue
87 DIS[idx[0],idx[1]]=dist[nam2dis[Nplg[n]]]
88 nc.variables['NO'][0,0,:,:]=DIS[:,:]
89 nc.close()
90
- 將模版製作成最終之網格遮罩(gridmask)檔案
- 切割時間長度
- 新增每個分區的變數名稱、單位、敘述等內容
- 按照每個編號的網格位置,填入1.0的值
- 最後再將原有模版中的變數(
NO及PM25)予以去除
91 ncks=subprocess.check_output('which ncks',shell=True).decode('utf8').strip('\n')
92 system(ncks+' -O -d TSTEP,0,0 PM25_202001-05_d1.nc AQFZones_EAsia_81K.nc')
93 nc1=netCDF4.Dataset('AQFZones_EAsia_81K.nc','r+')
94 for i in set(DIS.flatten()):
95 s='AQFZ'+str(int(i))
96 nc1.createVariable(s,"f4",("TSTEP","LAY","ROW","COL"))
97 nc1.variables[s].units = "fraction "
98 nc1.variables[s].long_name = "China Air Quality Forecast Zone: "+s[-1]
99 nc1.variables[s].var_desc = "fractional area per grid cell,1:JJZ,2:FWShanXi,3:DongBei,4:XiBei,5:HuaNan,6:Xinan,7:HuaDong"
100 idx=np.where(DIS==i)
101 nc1.variables[s][:,:,:,:]=0
102 for j in range(len(idx[0])):
103 nc1.variables[s][0,0,idx[0][j],idx[1][j]]=1.
104 nc1.close()
105 system(ncks+' -O -x -v NO,PM25 AQFZones_EAsia_81K.nc a;mv a AQFZones_EAsia_81K.nc')
106
程式下載
成果檢視
中國大陸空品質量預報分區圖 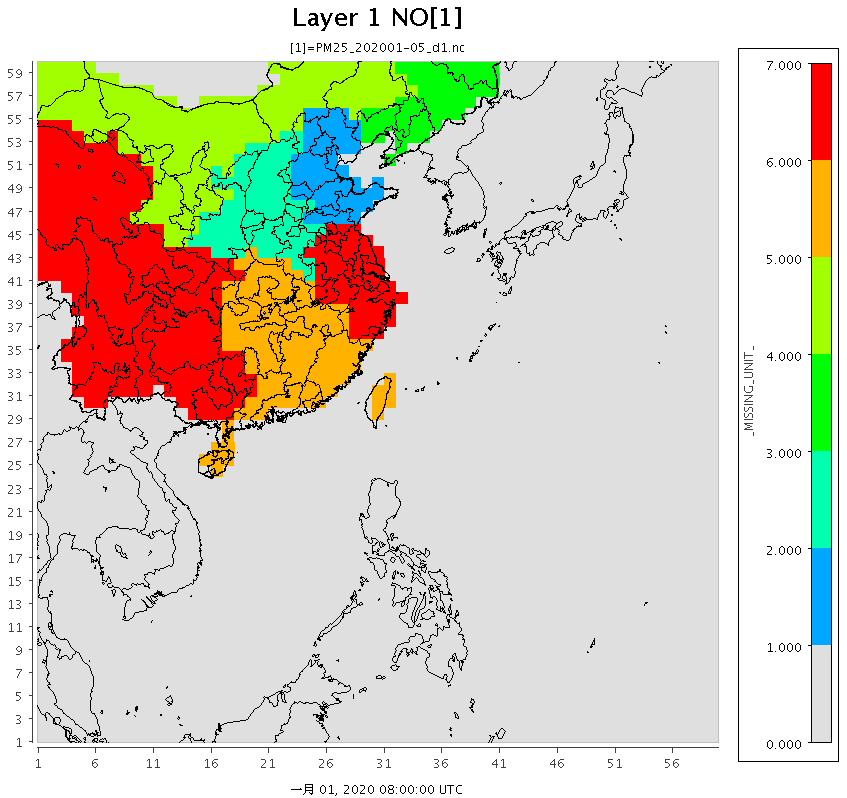
Reference
- USEPA, Integrated Source Apportionment Method (CMAQ-ISAM), CMAQ User’s Guide (c) 2021, github, Latest commit on 18 Aug, 2021
- Tyler Erickson, pyKML v0.1.0 documentation,pythonhosted, 2011
- Sean Gillies, Shapely 1.8.0 pypi, Oct 26, 2021