地面排放檔之轉換(CMAQ)
Table of contents
背景
- REAS (Regional Emission inventory in ASia)是日本國立環境研究所公開的亞洲地區空氣污染及溫室氣體排放量資料庫,詳見官網之說明。
- REAS數據雖然不是最新、但也是持續發展、更新的資料庫系統,目前官網提供的是2021年的REAS3.2.1版。
- 除電廠等主要污染源外,其地面污染源解析度為0.25度,在台灣地區約為25~27公里,正好為d02的網格解析度。
- 座標系統轉換程式的困難點在於如何在過程中保持質量守恆。策略上:
- 如果新網格網格間距大於0.25度(如d1 81Km),則採加總方式,將新網格內的REAS排放量予以加總成該網格排放量,能夠維持總量守恆,對於空間變化較大的類別如交通及工業,有可能位置會有些失焦。見reas2cmaqD1.py程式說明
- 如新網格網格間為相當或小於0.25度(如d0 CWB WRF_15Km 或d2 27Km),則採REAS網格之內插,可能總量會略有差異(因平滑處理後會較為低一些),但分布特徵應能維持。詳見reas2cmaqD1.py程式說明
- 過去曾經作法
- MM5及REASv1時代曾經使用MM5正交網格之經緯度為格線,切割REAS排放量,累積各網格排放量。
- 廢棄不繼續執行的理由:Fortran程式散失、網格系統無法更新。
- REASv2~REASv3.1時代曾使用CAMx系統的bndextr程式系統來進行切割及整併。該程式設計成可以從Mozart等間距經緯度之濃度檔,切割出直角座標系統之ic與bc,而該ic檔即為uamiv格式之檔案,只需正確轉換單位即可成為排放量檔案。
- MM5及REASv1時代曾經使用MM5正交網格之經緯度為格線,切割REAS排放量,累積各網格排放量。
reas2cmaqD2.py程式說明
2個間距相近的不同網格系統進行空間內插,程式設計較為單純,優先予以說明。
程式執行
- 需要引數:domain_name(
D0、D2)、category_number(0~10)for icat in {0..10};do sub python reas2cmaqD2.py D0 $icat done - sub=
$1 $2 $3 $4 $5 $6 $7 $8 $9 ${10} ${11} ${12} ${13} ${14} ${15} ${16} ${17} ${18} ${19} ${20} & - 各排放類別處理完後,可就欲研究的主題進行合併,可以使用addNC工具將同樣規格的nc檔案予以相加,如下例即將11類之nc檔合併成為2015_D0.nc:
addNC FERTILIZER_D0.nc MISC_D0.nc ROAD_TRANSPORT_D0.nc DOMESTIC_D0.nc INDUSTRY_D0.nc OTHER_TRANSPORT_D0.nc SOLVENTS_D0.nc WASTE_D0.nc EXTRACTION_D0.nc MANURE_MANAGEMENT_D0.nc POWER_PLANTS_NON-POINT_D0.nc 2015_D0.nc
分段說明
- 調用模組
- 使用scipy的griddata進行內插
import numpy as np
import netCDF4
import sys, os
from pandas import *
from pyproj import Proj
from scipy.interpolate import griddata
- 因REAS壓縮檔內的目錄結構參差不齊,使用findc來確定檔案位置,將路徑結果存成文字檔fnames.txt備用
- 讀取檔案。REAS文件檔中有
/mon該行,行前有污染物質名稱,將其與檔名一起輸出,以形成dict(specn)的內容
- 讀取檔案。REAS文件檔中有
os.system('~/bin/findc "REASv*" >fnames.txt')
os.system('for i in $(cat fnames.txt);do echo $i $(grep "/mon" $i|cut -d[ -f1);done >spec.txt')
with open('spec.txt','r') as f:
l=[i.strip('\n').strip('_') for i in f]
fname_spec={i.split()[0]:i.split()[1] for i in l}
spec=list(set(fname_spec.values()))
spec.sort()
nspec=len(spec)
specn={spec[i]:i for i in range(nspec)}
fnames=list(fname_spec)
nmv=set([fname_spec[f] for f in fnames if 'NMV' in f])
specNonV=set([fname_spec[f] for f in fnames if 'NMV' not in f]) #共9種CNPS,part(BC,OC,PM2.5,PM10),CO2,ACNS
- 讀取REAS之網格座標。因每檔案長度不一,須全讀過一遍,找到經緯度的極值,確認後再行產生網格系統。
- 將其轉成直角座標系統(
x,y)備用
- 將其轉成直角座標系統(
#read the coordinates
lon,lat=[],[]
for fname in fnames:
if '0.25x0.25' not in fname:continue
with open(fname,'r') as f:
l=[i.strip('\n').strip('_') for i in f]
if len(l)<=9:continue
lon=list(set(lon+[float(i.split()[0]) for i in l[9:]]))
lat=list(set(lat+[float(i.split()[1]) for i in l[9:]]))
# generate the x and y arrays for REAS datafile
for ll in ['lon','lat']:
exec(ll+'.sort()')
exec('n'+ll+'=nn=int(('+ll+'[-1]-'+ll+'[0])/0.25)+1')
exec(ll+'M=['+ll+'[0]+0.25*i for i in range(nn)]')
exec(ll+'n={l:'+ll+'M.index(l) for l in '+ll+'M}')
lonm, latm = np.meshgrid(lonM, latM)
- 讀取模版,建立新(CMAQ)、舊(REAS)座標系統的對照關係,以便進行griddata內插
- 座標轉換(pnyc)須讀取模版的中心點位置(
lat_0=nc.YCENT, lon_0=nc.XCENT),如此才能得到正確的相對位置。
- 座標轉換(pnyc)須讀取模版的中心點位置(
#interpolation indexing from template # get the argument
tail=sys.argv[1]+'.nc'
fname='template'+tail
nc = netCDF4.Dataset(fname, 'r')
V=[list(filter(lambda x:nc.variables[x].ndim==j, [i for i in nc.variables])) for j in [1,2,3,4]]
nt,nlay,nrow,ncol=nc.variables[V[3][0]].shape
x1d=[nc.XORIG+nc.XCELL*i for i in range(ncol)]
y1d=[nc.YORIG+nc.YCELL*i for i in range(nrow)]
x1,y1=np.meshgrid(x1d,y1d)
maxx,maxy=x1[-1,-1],y1[-1,-1]
minx,miny=x1[0,0],y1[0,0]
pnyc = Proj(proj='lcc', datum='NAD83', lat_1=10, lat_2=40, lat_0=nc.YCENT, lon_0=nc.XCENT, x_0=0, y_0=0.0)
x,y=pnyc(lonm,latm, inverse=False)
boo=(abs(x) <= (maxx - minx) /2+nc.XCELL*10) & (abs(y) <= (maxy - miny) /2+nc.YCELL*10)
idx = np.where(boo)
mp=len(idx[0])
xyc= [(x[idx[0][i],idx[1][i]],y[idx[0][i],idx[1][i]]) for i in range(mp)]
- 類別之定義
- 早期REAS有多達22種,然只有少數11類進行更新。
- 此處將類別迴圈在程式外部進行,以減省執行時間
# category of REAS emission files
cate=['DOMESTIC', 'EXTRACTION', 'FERTILIZER', 'INDUSTRY', 'MISC', 'SOLVENTS', 'WASTE',
'ROAD_TRANSPORT', 'OTHER_TRANSPORT', 'POWER_PLANTS_NON-POINT', 'MANURE_MANAGEMENT']
cate.sort()
ncat=len(cate)
catn={cate[i]:i for i in range(ncat)}
- 將所有REAS文字檔內容讀成矩陣備用
- REAS文字檔每行有經、緯度、及12個月的排放量(噸數),共有14個值。先將其整個序列轉成array再重整(reshape)。因每個檔案長度不一(
lenl),不能定型化來讀取。 - 此處使用dict(
latn,lonn)而不是執行序列的index函數來標定經緯度,會比較快速。
- REAS文字檔每行有經、緯度、及12個月的排放量(噸數),共有14個值。先將其整個序列轉成array再重整(reshape)。因每個檔案長度不一(
# read the monthly REAS emissions and store in var matrix
var=np.zeros(shape=(ncat,nspec,12,nlat,nlon))
for fname in fnames:
if '0.25x0.25' not in fname:continue
icat=-1
for c in cate:
if c in fname:icat=catn[c]
if icat==-1:continue
ispec=specn[fname_spec[fname]]
with open(fname,'r') as f:
l=[i.strip('\n').strip('_') for i in f]
if len(l)<=9:continue
lenl=len(l[9:])
arr=np.array([float(i.split()[j]) for i in l[9:] for j in range(14)]).reshape(lenl,14)
for i in range(lenl):
var[icat,ispec,:,latn[arr[i,1]],lonn[arr[i,0]]]=arr[i,2:]
print(fname)
- REAS2CMAQ對照表
# spec name dict
df=read_csv('REAS2CMAQ.csv')
c_dup=[i for i in set(df.CMAQ) if list(df.CMAQ).count(i)>1]
REAS2CMAQ={i:j for i,j in zip(df.REAS,df.CMAQ) if i in spec}
r_dup=[i for i in REAS2CMAQ if REAS2CMAQ[i] in c_dup and i in spec]
r_mole={i:j for i,j in zip(df.REAS,df.mole)}
- 此處將類別迴圈在程式外部進行,以減省執行時間。
- 讀取第2引數:
icat - 將模版複製成預期結果檔案
- 讀取第2引數:
icat=int(sys.argv[2])
#for icat in range(ncat):
fname=cate[icat]+'_'+tail
os.system('cp template'+tail+' '+fname)
nc = netCDF4.Dataset(fname, 'r+')
- 延長檔案並將排放量全填0(準備累加、並避免被遮蔽)
- REAS為逐月檔案。此階段先將內容存成12個小時的frame。後續再按不同類別進行時間的劃分(月排放量轉成逐時排放)。
# elongate the new ncf
for t in range(12):
nc['TFLAG'][t,:,1]=t*100*100
nc['TFLAG'][:,:,0]=nc.SDATE
# fill the new nc file
for v in V[3]:
nc[v][:]=0.
- 物質對照及排除機制
#interpolation scheme, for D0/D2 resolution(15Km/27Km)
for v in spec:
ispec=specn[v]
if np.sum(var[icat,ispec,:,:,:])==0.:continue
if v not in REAS2CMAQ:continue
vc=REAS2CMAQ[v]
if vc not in V[3]:continue
- 逐月進行空間內插
- 對超過REAS範圍的新網格位置,griddata無法進行外插,因此會變成nan,須將其設成0,否則會被遮蔽。
zz=np.zeros(shape=(12,nrow,ncol))
for t in range(12):
c = np.array([var[icat,ispec,t,idx[0][i], idx[1][i]] for i in range(mp)])
zz[t,:,: ] = griddata(xyc, c[:], (x1, y1), method='linear')
zz=np.where(np.isnan(zz),0,zz)
- r_dup結果須累加。
- 單位為106mole/month
if v in r_dup:
nc[vc][:,0,:,:]+=zz[:,:,:]*r_mole[v]/mw[v]
- 非r_dup結果不需累加
- 單位為106mole/month
else:
nc[vc][:,0,:,:] =zz[:,:,:]*r_mole[v]/mw[v]
nc.close()
reas2cmaqD1.py程式說明
- 如前所述,D1網格間距81Km,將會有3~4格REAS排放量,如用內插作法將會嚴重失真,此處乃以加總之策略進行座標系統轉換。
- 在網格線附近的排放量,會因為歸併在特定某一格而造成略有偏差,對於排放量空間變化較大之污染類別,如交通、工業等,可能會造成較大的偏差。
執行
- reas2cmaqD1.py沒有引數、所有排放類別都在程式內部依序執行
- 此一作法雖然無法同步或平行化,然因程序較為單純,花費時間反而較REAS2時代的bndextr法更加快速、有效。
- 使用np.sum函數,也會較fortran更加快速。
結果
- REAS 類別:
cate=['DOMESTIC', 'EXTRACTION', 'FERTILIZER', 'INDUSTRY', 'MISC', 'SOLVENTS', 'WASTE', 'ROAD_TRANSPORT', 'OTHER_TRANSPORT', 'POWER_PLANTS_NON-POINT', 'MANURE_MANAGEMENT']共11類 - 結果檔名:
fname=cate[icat]+'_D1.nc'
程式差異
- 使用np.searchsorted找到新網格座標在REAS座標系統的位置(
lat_ss,lon_ss)- 因CMAQ最後一格還在REAS範圍內,需要在CMAQ的東、北方多加一圈,假設括進格數與倒數一格相同。
- searchsorted詳純淨天空
- 同樣作法見MOZARD/WACCM模式輸出轉成CMAQ初始條件_垂直對照
lon_ss, lat_ss= np.zeros(shape=(nrow+1,ncol+1), dtype=int)-1, np.zeros(shape=(nrow+1,ncol+1), dtype=int)-1
for ll in ['lon','lat']:
llss =ll+'_ss'
lls = np.zeros(shape=(nrow,ncol), dtype=int)-1
exec('lls=np.searchsorted('+ll+'M,'+ll+')')
exec(llss+'[:nrow,:ncol]=lls[:,:]')
for i in range(ncol):
exec(llss+'[nrow,i]=lls[-1,i]*2-lls[-2,i]')
for j in range(nrow):
exec(llss+'[j,ncol]=lls[j,-1]*2-lls[j,-2]')
exec(llss+'[nrow,ncol]=lls[-1,-1]*2-lls[-2,-2]')
- 使用np.sum函數,指定在row及col維度(
axis=(1,2))進行加總
for v in r_dup:
...
for j in range(nrow):
for i in range(ncol):
nc[vc][:,0,j,i]+=np.sum(var[icat,ispec,:,lat_ss[j,i]:lat_ss[j+1,i+1],lon_ss[j,i]:lon_ss[j+1,i+1]],axis=(1,2))*r_mole[v]/mw[v]
for v in set(spec)-set(r_dup):
...
for j in range(nrow):
for i in range(ncol):
nc[vc][:,0,j,i]=np.sum(var[icat,ispec,:,lat_ss[j]:lat_ss[j+1],lon_ss[i]:lon_ss[i+1]],axis=(1,2))*r_mole[v]/mw[v]
程式下載
Download: 加總方式:reas2cmaqD1.py
Download: 內插方式:reas2cmaqD2.py
結果檢視
- m3.nc檔案可以用VERDI檢視,如以下:
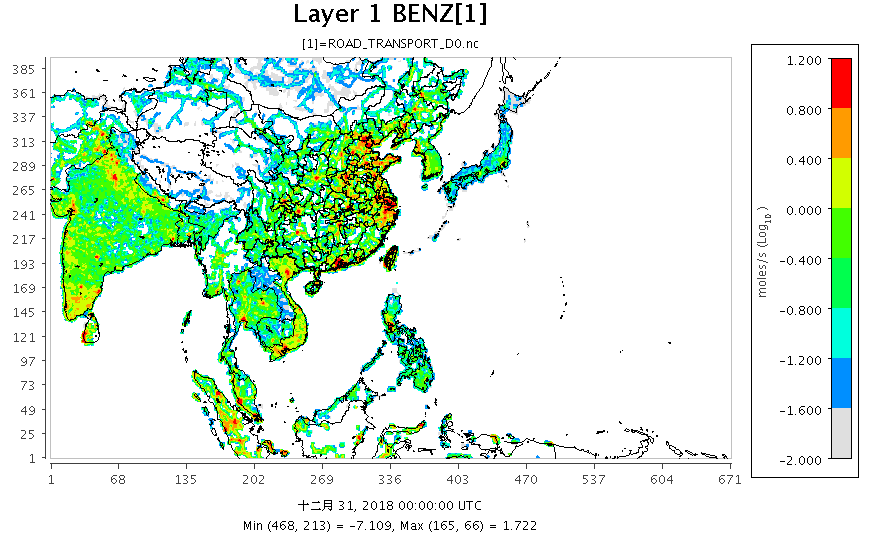 |
|---|
| 圖 d00範圍REAS 2015年1月道路交通BENZ排放量之分布 |
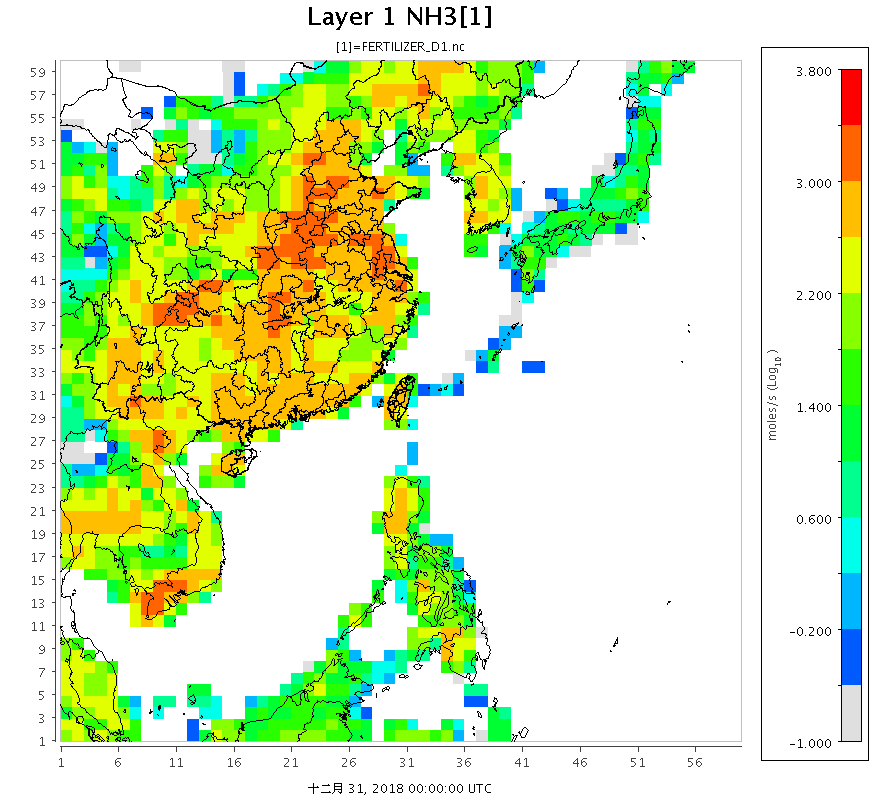 |
| 圖 d01範圍REAS 2015年1月肥料NH3排放量之分布 |
其他作業
其他網格系統之排放量檔案
- D5 (cwbWRF_3Km)以cubicspline方法進行內插,範圍因靠近跨日線,經度會出現負值,座標轉換會出錯,需小心取範圍。
#kuang@master /nas1/TEDS/REAS3.2/origins
#$ diff reas2cmaqD2.py reas2cmaqD5.py
53c53
< boo=(x<=maxx+nc.XCELL*10) & (x>=minx-nc.XCELL*10) & (y<=maxy+nc.YCELL*10) & (y>=miny-nc.YCELL*10)
---
> boo=(abs(x) <= (maxx - minx) /2+nc.XCELL*10) & (abs(y) <= (maxy - miny) /2+nc.YCELL*10)
115c115
< zz[t,:,: ] = griddata(xyc, c[:], (x1, y1), method='linear')
---
> zz[t,:,: ] = griddata(xyc, c[:], (x1, y1), method='cubic')
- D6 (HUADON_3k)範圍之排放量準備,也是以內插方式(reas2cmaqD2.py)求取。
2018年4月案例之應用
- 直接以ncks -d,將4月份值從2015_d?.nc取出在2018年4月的模擬案例中應用
- 以gen_emis.py修改TFLAG,並將月均值複製,以產生CMAQ所需的逐時檔
- 並未做年度間與日變化的調整
#kuang@master /nas1/cmaqruns/2018base/data/emis/EDGAR_HUADON_3k
#$ cat gen_emis.py
import netCDF4
import numpy as np
import datetime
from dtconvertor import dt2jul, jul2dt
bdate=datetime.datetime(2018,3,30)
sdate=[bdate+datetime.timedelta(days=i) for i in range(10)]
ib=0
for t in range(ib,10):
ymd=sdate[t].strftime('%Y%m%d')
fname='1804/area_HUADON_3k.'+ymd+'.nc'
nc = netCDF4.Dataset(fname,'r+')
if t==ib:V=[list(filter(lambda x:nc.variables[x].ndim==j, [i for i in nc.variables])) for j in [1,2,3,4]]
nc.SDATE,nc.STIME=dt2jul(sdate[t])
for h in range(25):
nc['TFLAG'][h,:,0],nc['TFLAG'][h,:,1]=dt2jul(sdate[t]+datetime.timedelta(hours=h))
for v in V[3]:
nc[v][h,0,:,:]=nc[v][0,0,:,:]
nox=nc['NO'][:]+nc['NO2'][:]
nc['NO'][:] = 0.9*nox[:]
nc['NO2'][:] = 0.1*nox[:]
nc.close()
以氣溫進行年度校正
REASv3.1時代曾以WRF模擬之地面氣溫(T2)月均值,與2015年月均排放量進行回歸,並將斜率應用在目標年逐時排放的推估。雖然當時的排放檔案格式為uamiv,其邏輯應可以應用在此處2015_d?.nc的展開。
- 程式名稱:mkMon3.py
- 引數:程式需要2個引數,月份與粗網格層數(“d1”或”d2”)
- 需要檔案
- 2015及目標年WRF氣溫檔案
- 月均排放量檔案
- 產生檔案:全月逐時排放量
Download: 氣溫年度校正:mkMon3.py
Reference
- USEPA(2019), GC namelist for cb6r3_ae7_aq, Latest commit on 29 May 2019.
- National Institute for Environmental Studies(2021), Regional Emission inventory in ASia (REAS) Data Download Site, 23-December-2021.
- 純淨天空, Python numpy.searchsorted()用法及代碼示例 vimsky