CAMx地面點源排放檔案之產生
背景
- 地面點源排放檔最大的特徵就是與其他面源一樣的格式,是網格化的分布,因此點源非但是某一切分煙囪高度以下的總合,也是某一網格解析度範圍內的總合。其逐時變化要先行展開,再針對網格範圍進行整併。
- 須先行產生地面點源每一污染源的時變係數檔案,詳地面點源之時變係數。
- 排放量整體處理原則參見處理程序總綱、針對點源之處理及龐大
.dbf檔案之讀取,為此處之前處理。程式也會呼叫到ptse_sub中的副程式
程式說明
程式執行
因排放物質類別與污染源製造程序的特徵有關,必須分開個別處理,此處則以個別污染項目執行ptseG_ONS.py,執行方式如下:
for spe in NMHC SNCP;do python ptseG_ONS.py $spe;done
- 由於程式消耗記憶體非常大量,如要同時進行,需注意記憶體的使用情形。
- 污染源個數與排放高度限值的設定、地面PM排放條件之給定、以及數據年代等等都有關係,需配套紀錄。
程式差異
diff ptseG.py ptseE.py
- 調用模組,
ptseG多調用pv_nc、disc2個程式,也有些沒有調用。
kuang@node03 /nas1/TEDS/teds11/ptse
$ diff ptseG.py ptseE.py
12c12,13
< from ptse_sub import CORRECT, add_PMS, check_nan, check_landsea, FillNan, WGS_TWD, Elev_YPM, pv_nc, disc
---
> from mostfreqword import mostfreqword
> from ptse_sub import CORRECT, add_PMS, check_nan, check_landsea, FillNan, WGS_TWD, Elev_YPM
13a15
> from cluster_xy import cluster_xy, XY_pivot
- 用不一樣的模版,須使用地面排放源的模版
- 檔名不一樣
30c36,37
< fname='fortBE.413_teds10.ptsG'+mm+'.nc'
---
> print('template applied')
> NCfname='fortBE.413_teds10.ptsE'+mm+'.nc'
32c39
< nc = netCDF4.Dataset(fname, 'r+')
---
> nc = netCDF4.Dataset(NCfname, 'r+')
34,35c41,42
< os.system('cp '+P+'template_d4.nc '+fname)
< nc = netCDF4.Dataset(fname, 'r+')
---
> os.system('cp '+P+'template_v7.nc '+NCfname)
> nc = netCDF4.Dataset(NCfname, 'r+')
- 地面排放量是4維陣列,點源除了排放量之外,也有3維陣列(煙道參數)
- 屬性標籤
37,38c44,45 < nt,nlay,nrow,ncol=nc.variables[V[3][0]].shape < nv=len(V[3]) --- > nt,nv,dt=nc.variables[V[2][0]].shape > nv=len([i for i in V[1] if i !='CP_NO']) 41c48 < nc.NOTE='grid Emission' --- > nc.NOTE='Point Emission' 42a50 > nc.NVARS=nv 44c52,53 < #nc.NAME='EMISSIONS ' --- > nc.name='PTSOURCE ' > nc.NSTEPS=ntm 55,56c64 < for v in V[3]: < nc.variables[v][:]=0. --- > nc.close() - 對切分高度的作法,還包括所有煙道編號不是以
P起頭的所有污染源
70,71c84,85
< #shorter stack or all NO_S other than 'P'
< boo=(df.HEI<Hs) | (df.NO_S.map(lambda x:x[0]!='P'))
---
> #only P??? an re tak einto account
> boo=(df.HEI>=Hs) & (df.NO_S.map(lambda x:x[0]=='P'))
- 點源須針對煙道重新整理資料庫,因為需要煙囪參數。地面點源不需要。
87,88c101,114
< print('NMHC expanding')
< dfV=df.loc[df.NMHC_EMI>0].reset_index(drop=True)
---
> #pivot table along the dimension of NO_S (P???)
> df_cp=pivot_table(df,index='CP_NO',values=cole+['ORI_QU1'],aggfunc=sum).reset_index()
> df_xy=pivot_table(df,index='CP_NO',values=XYHDTV+colT,aggfunc=np.mean).reset_index()
...
> #determination of camx version
> ver=7
> if 'XSTK' in V[0]:ver=6
> print('NMHC/PM splitting and expanding')
- 資料庫以外新的SCC是在執行過程中發現的,地面與高空自然會有不同
107,113c133,141
---
> '30301024':'30301014',
> '30400213':'30400237',
> '30120543':'30120502',
- 因
ons矩陣為整數,沒有常態化的必要,因此排放量的時間單位須在此處一併處理
155,156c183
< dfV[c]=0.
< dfV.NMHC_EMI=[i*1E6/j/k for i,j,k in zip(dfV.NMHC_EMI,dfV.DY1,dfV.HD1)]
---
> df[c]=0.
- 時變係數檔案名稱差異
168,169c196,201
< 'NMHC':'NMHC_CP9348_MDH8760_ONS.bin',
< 'SNCP':'SNCP_CP4072_MDH8760_ONS.bin'}
---
> 'CO' :'CO_ECP7496_MDH8760_ONS.bin',
> 'NMHC':'NMHC_ECP2697_MDH8760_ONS.bin',
> 'NOX' :'NOX_ECP13706_MDH8760_ONS.bin',
> 'PM' :'PM_ECP17835_MDH8760_ONS.bin',
> 'SOX' :'SOX_ECP8501_MDH8760_ONS.bin'}
>
171,172c203,207
< 'NMHC':'NMHC_CP9897_MDH8760_ONS.bin',
< 'SNCP':'SNCP_CP9188_MDH8760_ONS.bin'}
---
> 'CO' :'CO_ECP4919_MDH8784_ONS.bin',
> 'NMHC':'NMHC_ECP3549_MDH8784_ONS.bin',
> 'NOX' :'NOX_ECP9598_MDH8784_ONS.bin',
> 'PM' :'PM_ECP11052_MDH8784_ONS.bin',
> 'SOX' :'SOX_ECP7044_MDH8784_ONS.bin'}
174,175c209,213
< 'NMHC':'NMHC_CP12581_MDH8784_ONS.bin',
< 'SNCP':'SNCP_CP22614_MDH8784_ONS.bin'}
---
> 'CO' :'CO_ECP1077_MDH8784_ONS.bin',
> 'NMHC':'NMHC_ECP1034_MDH8784_ONS.bin',
> 'NOX' :'NOX_ECP1905_MDH8784_ONS.bin',
> 'PM' :'PM_ECP2155_MDH8784_ONS.bin',
> 'SOX' :'SOX_ECP1468_MDH8784_ONS.bin'}
- 整數的
ons,binary檔案讀法有點不一樣,其餘作法大同小異。
178,239c216,228
< fnameO=fns['NMHC']
< with FortranFile(fnameO, 'r') as f:
< cp = f.read_record(dtype=np.dtype('U12'))
< mdh = f.read_record(dtype=np.int)
< ons = f.read_record(dtype=np.int)
< ons=ons.reshape(len(cp),len(mdh))
...
矩陣作法說明
此處說明全年排放量與時變係數相乘的矩陣作法。由於每個分項的階級數都不一致,如何不使用迴圈直接以矩陣形態相乘?
- 宣告3個一樣階級數、一樣大小的矩陣,分別代表全年排放量、時變係數、以及逐時結果矩陣
- 因污染項目在資料庫表中是橫向不同的欄位。還好個數不多(
len(cbm)=16),用迴圈執行即可。 - 全年排放量沒有時間的維度,填入
None - 時變係數沒有污染項目的維度,同樣填入
None - 如此乘數與被乘數的矩陣形態完全一致,直接相乘即可。
- 因污染項目在資料庫表中是橫向不同的欄位。還好個數不多(
201 NREC,NC=len(dfV2),len(cbm)
202 VOC,a,b=(np.zeros(shape=(NREC,ntm,NC)) for i in range(3))
203 for c in cbm:
204 ic=cbm.index(c)
205 a[:,:,ic]=np.array(dfV2[c])[:,None]
206 b[:,:,:]=ons2[:,:,None]
207 VOC[:,:,:]=a[:,:,:]*b[:,:,:]
208 col=['IX','IY']+cbm
209 pv_nc(dfV2[col],nc,VOC)
210 a,b,VOC=0,0,0
結果檢視
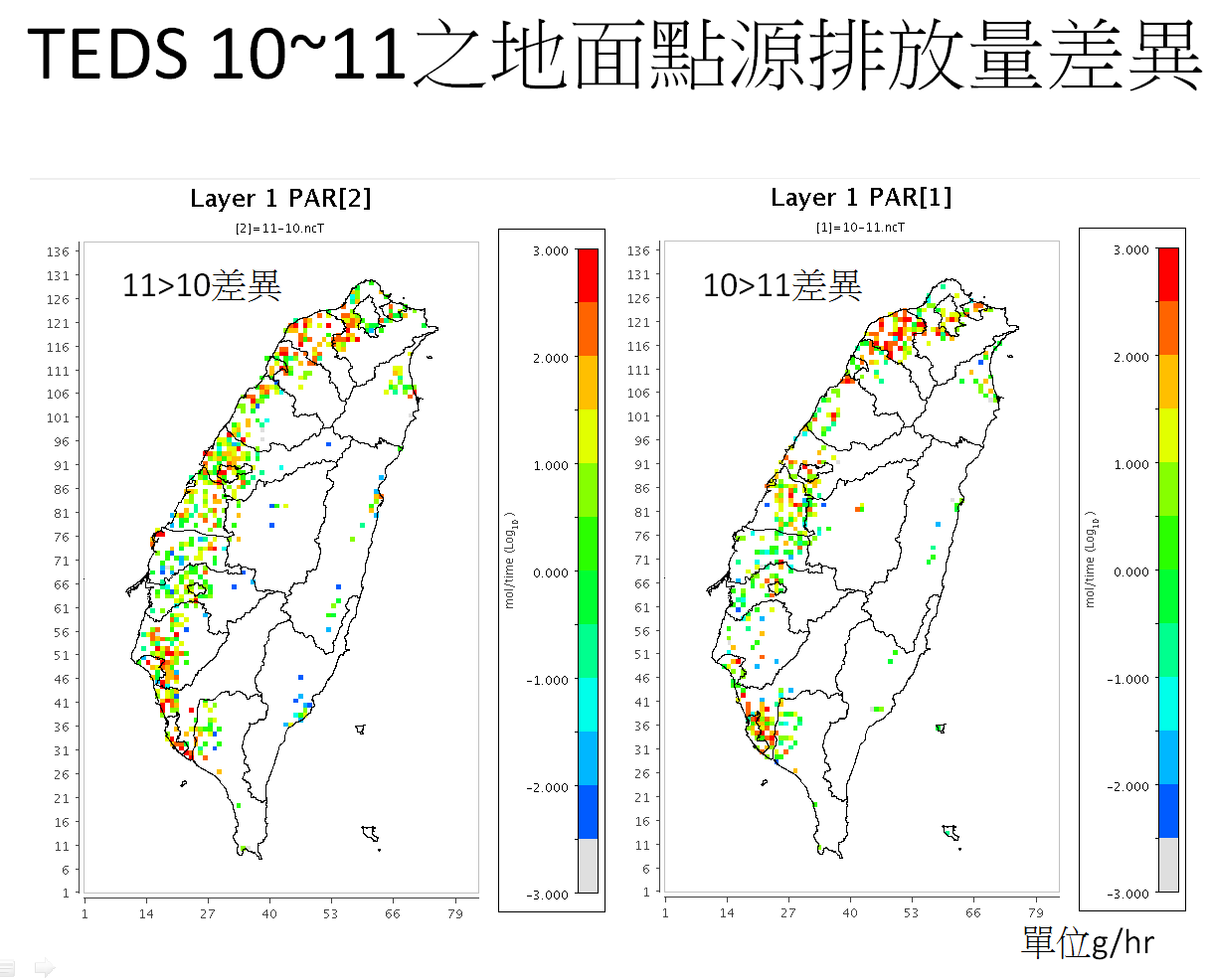
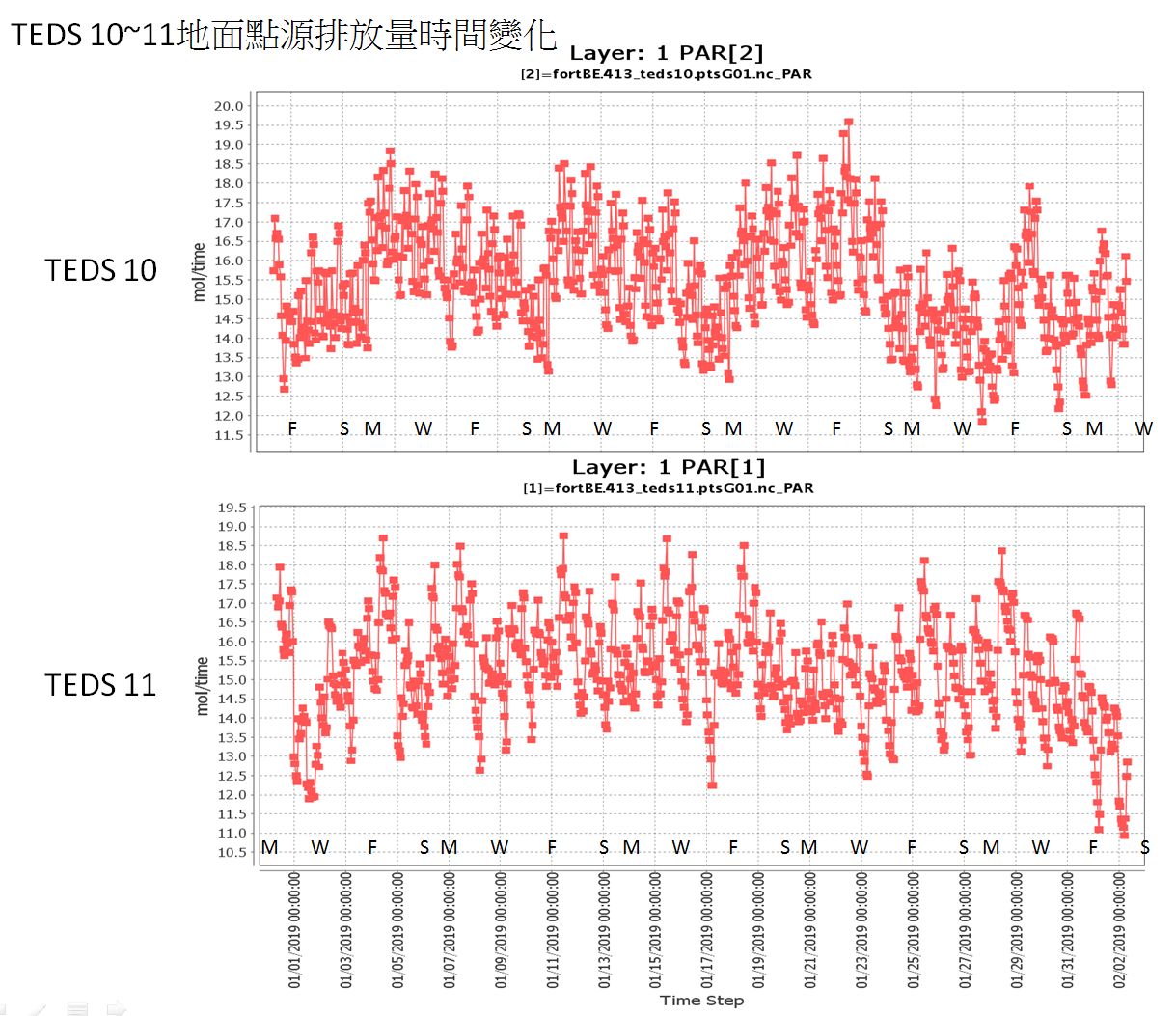
Download: python程式:ptseG.py