CAMx高空排放檔之網格化
背景
高空點源排放檔案沒有適用的顯示軟體。須轉成其他格式,此處以d04範圍地面排放量檔案格式為目標,該格式可以在VERDI或MeteoInfo中開啟。
程式說明
程式執行
- pt2em_d04.py只需要一個引數,就是CAMx點源排放量檔案。
- 程式會以
template_d4.nc為模版,將點源排放量予以網格化填入模版相對應位置。 - 時間標籤則與輸入檔案一致。
pt2em_d04.py fortBE.413_teds10.ptsE01.nc
- 執行結果檔案會再輸入檔名稱後加上
_d04.nc,以標示其網格系統特性。
程式分段說明
- 調用模組
#kuang@node03 /nas1/TEDS/teds11/ptse
#$ cat -n pt2em_d04.py
1 import netCDF4
2 import numpy as np
3 import datetime
4 import os, sys, subprocess
5 from pandas import *
6
- 重要相依性
- 取得
ncks、ncatted等程式之位置 - 取得引數(高空點源檔案名稱)
- 取得
7 ncks=subprocess.check_output('which ncks',shell=True).decode('utf8').strip('\n')
8 ncatted=subprocess.check_output('which ncatted',shell=True).decode('utf8').strip('\n')
9 MM=sys.argv[1]
10 fname=MM
- 讀取高空排放量檔案(內設為CAMx 7版本)
- 變數讀取是最花時間的步驟
11 #store the point source matrix
12 nct = netCDF4.Dataset(fname,'r')
13 Vt=[list(filter(lambda x:nct.variables[x].ndim==j, [i for i in nct.variables])) for j in [1,2,3,4]]
14 ntt,nvt,dt=nct.variables[Vt[2][0]].shape
15 try:
16 nopts=nct.NOPTS
17 except:
18 nopts=nct.dimensions['COL'].size
19
20 TFLAG=nct.variables['TFLAG'][:,0,:]
21 ETFLAG=nct.variables['ETFLAG'][:,0,:]
22 SDATE=nct.SDATE
23 STIME=nct.STIME
24 Vt1=[i for i in Vt[1] if i not in ['CP_NO','plumerise']]
25 var=np.zeros(shape=(len(Vt1),ntt,nopts))
26 for v in Vt1:
27 iv=Vt1.index(v)
28 var[iv,:,:]=nct.variables[v][:,:]
29
- 開啟模版,並讀取網格系統之設定內容,用以計算網格位置標籤。
30 fname=MM+'_d04.nc'
31 os.system('cp template_d4.nc '+fname)
32 nc = netCDF4.Dataset(fname,'r+')
33 V=[list(filter(lambda x:nc.variables[x].ndim==j, [i for i in nc.variables])) for j in [1,2,3,4]]
34 nt,nlay,nrow,ncol=nc.variables[V[3][0]].shape
35 #determination of camx version and prepare IX/IY
36 ver=7
37 if 'XSTK' in Vt[0]:ver=6
38 X={6:'XSTK',7:'xcoord'}
39 Y={6:'YSTK',7:'ycoord'}
40 #store the coordinate system param. for calibration
41 for c in ['X','Y']:
42 for d in ['ORIG','CELL']:
43 exec(c+d+'=nc.'+c+d)
- 計算每根煙道的網格位置標籤(
IX,IY)備用
44 IX=np.array([(i-nc.XORIG)/nc.XCELL for i in nct.variables[X[ver]][:nopts]],dtype=int)
45 IY=np.array([(i-nc.YORIG)/nc.XCELL for i in nct.variables[Y[ver]][:nopts]],dtype=int)
46 nct.close()
47 nc.close()
48
- 篩選非為0的內容來輸出
- 如果確實有部分變數沒有內容,則從模版中予以去除,以減少檔案容量
49 #variable sets interception and with values
50 sint=[v for v in set(Vt1)&set(V[3]) if np.sum(var[Vt1.index(v),:,:])!=0.]
51 if len(sint)!=len(V[3]):
52 s=''.join([c+',' for c in set(V[3])-set(sint)])
53 ftmp=fname+'tmp'
54 res=os.system(ncks+' -O -x -v'+s.strip(',')+' '+fname+' '+ftmp)
55 if res!=0: sys.exit(ncks+' -x var fail')
56 ns=str(len(sint)-1)
57 res=os.system(ncks+' -O -d VAR,0,'+ns+' '+ftmp+' '+fname)
58 if res!=0: sys.exit(ncks+' -d VAR fail')
59 #template is OK
60
- 執行
pandas.pivot_table,以利用其平行處理功能。- 須將矩陣轉為資料表
61 #pivoting
62 ntm,NREC=ntt,nopts
63 sdt,ix,iy=(np.zeros(shape=(ntm*NREC),dtype=int) for i in range(3))
64 idatetime=np.array([i for i in range(ntt)],dtype=int)
65 for t in range(ntm):
66 t1,t2=t*NREC,(t+1)*NREC
67 ix[t1:t2]=IX
68 iy[t1:t2]=IY
69 for t in range(ntm):
70 t1,t2=t*NREC,(t+1)*NREC
71 sdt[t1:t2]=idatetime[t]
72 dfT=DataFrame({'YJH':sdt,'IX':ix,'IY':iy})
73 for v in sint:
74 iv=Vt1.index(v)
75 dfT[v]=var[iv,:,:].flatten()
76 pv=pivot_table(dfT,index=['YJH','IX','IY'],values=sint,aggfunc=sum).reset_index()
- 再將
pivot_table結果轉成矩陣輸出- 注意nc檔案並不適用np.array的fancy indexing,詳NC檔案多維度批次篩選
77 pv.IX=[int(i) for i in pv.IX]
78 pv.IY=[int(i) for i in pv.IY]
79 pv.YJH=[int(i) for i in pv.YJH]
80 boo=(pv.IX>=0) & (pv.IY>=0) & (pv.IX<ncol) & (pv.IY<nrow)
81 pv=pv.loc[boo].reset_index(drop=True)
82 imn,jmn=min(pv.IX),min(pv.IY)
83 imx,jmx=max(max(pv.IX)+abs(imn)*2+1,ncol), max(max(pv.IY)+abs(jmn)*2+1,nrow)
84 if imn<0 and imx+imn<ncol:sys.exit('negative indexing error in i')
85 if jmn<0 and jmx+jmn<nrow:sys.exit('negative indexing error in j')
86 idx=pv.index
87 idt=np.array(pv.loc[idx,'YJH'])
88 iy=np.array(pv.loc[idx,'IY'])
89 ix=np.array(pv.loc[idx,'IX'])
90 #reopen nc files and write time flags, and lengthen the span of time
91 nc = netCDF4.Dataset(fname,'r+')
92 for t in range(ntt):
93 for i in range(2):
94 nc.variables['TFLAG'][t,:,i]=TFLAG[t,i]
95 nc.variables['ETFLAG'][t,:,i]=ETFLAG[t,i]
96 nc.SDATE=SDATE
97 nc.STIME=STIME
98 #blanking all variables
99 for c in sint:
100 nc.variables[c][:]=0.
101 z=np.zeros(shape=(ntm,jmx,imx))
102 ss=np.array(pv.loc[idx,c])
103 #Note that negative indices are not bothersome and are only at the end of the axis.
104 z[idt,iy,ix]=ss
105 #also mapping whole matrix, NOT by parts
106 nc.variables[c][:,0,:,:]=z[:,:nrow,:ncol]
107 nc.close()
- 座標微調
- 這一段是早期使用twd97座標系統套用VERDI(內政部縣市
shape檔)時的誤差,改用經緯度後已無需要執行。
- 這一段是早期使用twd97座標系統套用VERDI(內政部縣市
108 #using CSC and XieHePP to calibrate the Map
109 xiheIXY_Verdi=(67,126) #fallen in the sea
110 xiheIXY_Target=(66,124)#calibrate with County border and seashore line
111 CSCIXY_Verdi=(20,30) #fallen in the KSHarbor
112 CSCIXY_Target=(21,31)
113 rateXY=np.array([(xiheIXY_Target[i]-CSCIXY_Target[i])/(xiheIXY_Verdi[i]-CSCIXY_Verdi[i]) for i in range(2)])
114 dxy_new=rateXY*np.array([XCELL,YCELL])
115 oxy_new=(1-rateXY)*dxy_new*np.array([ncol,nrow])/2.+np.array([XORIG,YORIG])
116 cmd1=' -a XCELL,global,o,f,'+str(dxy_new[0])
117 cmd2=' -a YCELL,global,o,f,'+str(dxy_new[1])
118 cmd3=' -a XORIG,global,o,f,'+str(oxy_new[0])
119 cmd4=' -a YORIG,global,o,f,'+str(oxy_new[1])
120 #ncatted -a XCELL,global,o,f,2872.340425531915 -a YCELL,global,o,f,2906.25 -a XORIG,global,o,f,-119074.46808510639 -a YORIG,global,o,f,-199078.125 fortBE.413_teds10.ptsE01.nc_d04.nc
121 #res=os.system(ncatted+cmd1+cmd2+cmd3+cmd4+' '+fname)
122 #if res!=0:sys.exit('fail ncatted')
123 sys.exit('fine!')
結果檢視
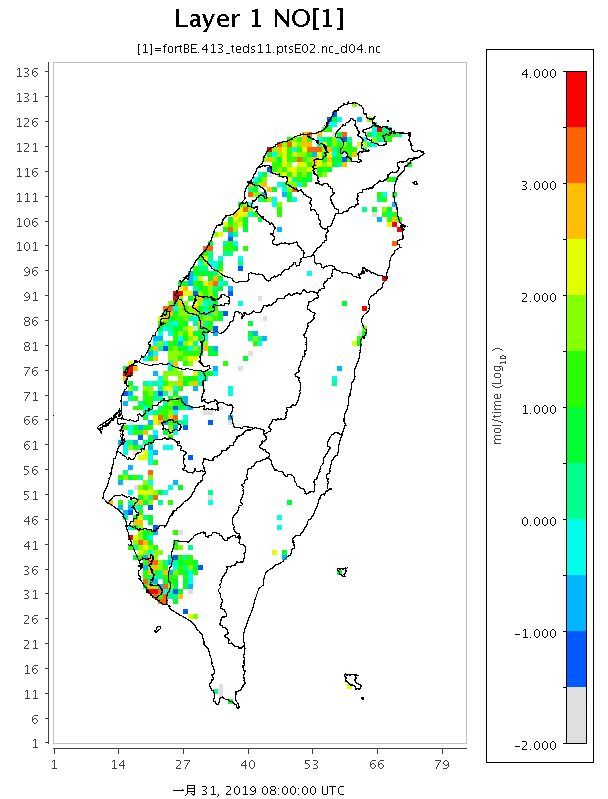
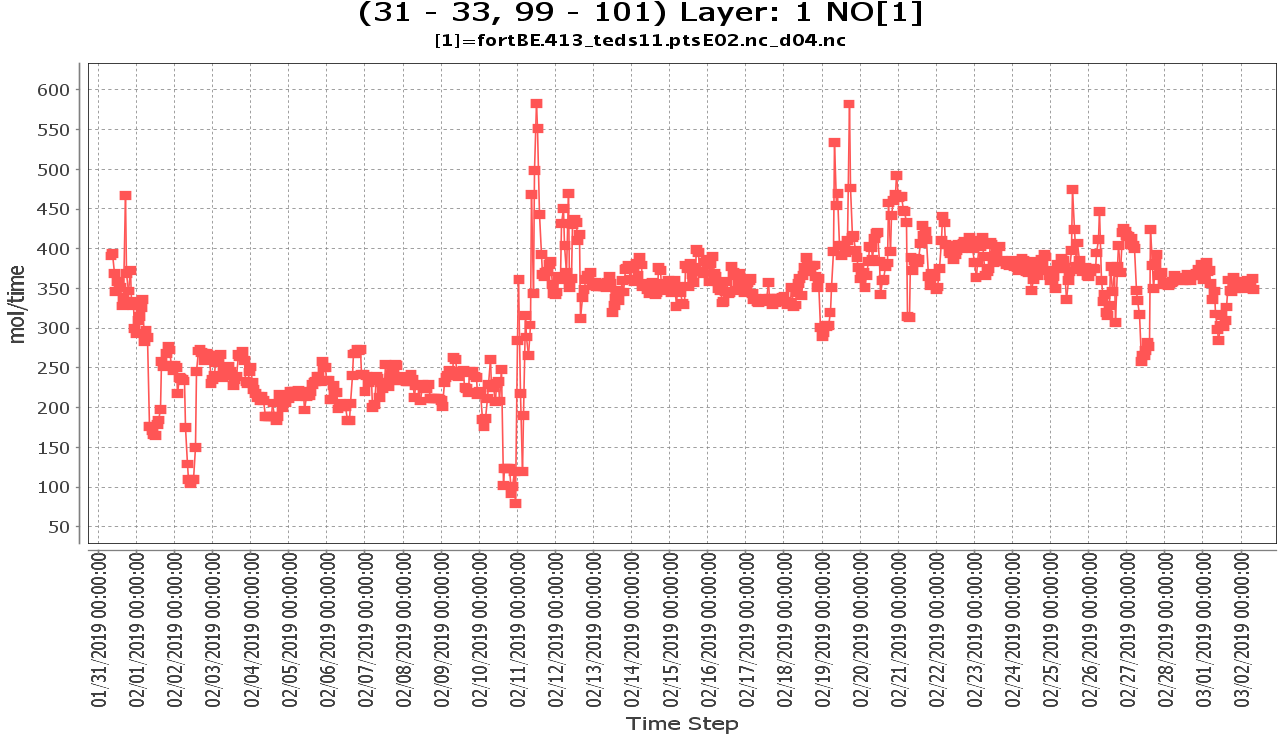
{kind=link}
Reference
- lizadams, Visualization Environment for Rich Data Interpretation (VERDI): User’s Manual, github, August 03, 2021
- Yaqiang Wang, MeteoInfo Introduction, meteothink, 2021,10,16