環保署測站數據鄉鎮區平均值之計算
背景
- 測站及鄉鎮區都是空間上的維度,但因為同一個鄉鎮區有可能有2個以上的測站,需要平均。還有更多的鄉鎮區並沒有測站,這需要內、外插。
- 平均方式:此處使用內積
np.dot方式,以加快計算速度。- 內積的定義
A[m,n] o B[n,l] = C[m,l](o為內積符號dot) - 讓
n為測站之維度,l為鄉鎮區。其他不改變的維度如日期、測項序等,則放在m。 - 讓
B[n,l]中的第1個維度的總和為1,如此就不會變化A的值,其結果為A的加權平均(此處各測站的加權都相同)。
- 內積的定義
- 內、外插方式有很多,此處以鄰近測站之值做為沒有測站鄉鎮區之值,依據town_aqstEnew.csv之關聯(參考CAM-chem模式結果之校正)。
- 時間上,本程式讀取全年日均值處理結果,詳說明。
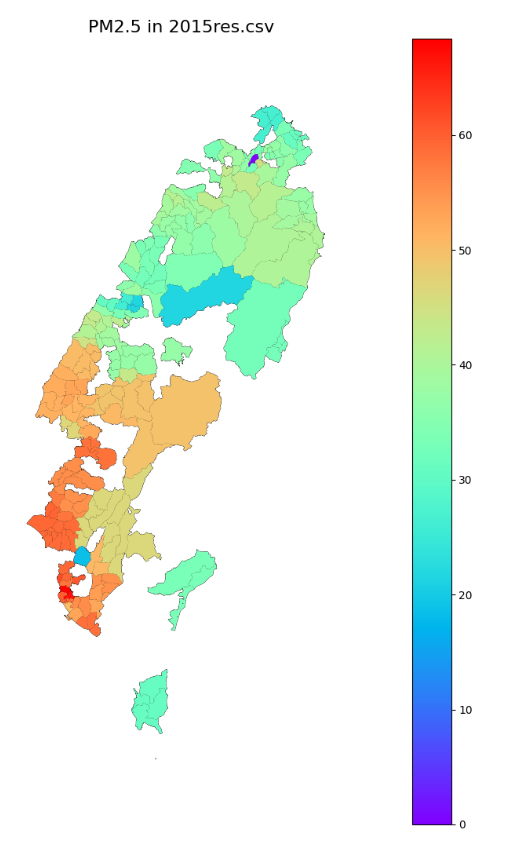
- 處理結果
- 以外積方式,將日期及鄉鎮區的維度向量,與1維的單位矩陣進行外積(
np.outer),以張開成為2維的矩陣,再壓平成為資料表格式輸出。 - 矩陣轉資料表過去的迴圈作法可以參考移動源排放檔案之轉檔-整併與輸出
- 檢視:參geoplot繪製行政區範圍等值圖
- 以外積方式,將日期及鄉鎮區的維度向量,與1維的單位矩陣進行外積(
程式基本
IO’s
- 引數
- 需要1個引數:年代(4碼)
- 鄉鎮區與測站編號的對照表town_aqstEnew.csv
- 輸出:YYYYres.csv
檔案讀取與測站之確認
- 因為跨了20年,測站及鄉鎮區的設定略有變更,須逐年測試、修正檢討。
yr=sys.argv[1]
fname='/nas1/CAM-chem/Annuals/town_aqstEnew.csv'
twn=read_csv(fname)
twn=twn.loc[twn.aq_st.map(lambda x:'0;' not in x)].reset_index(drop=True)
twn['stns']=[Series([int(i) for i in j[:-1].split(';')]) for j in twn.aq_st]
all_stn=[]
for i in twn.stns:
if len(i)==0:continue
a=all_stn+list(i)
all_stn=list(set(a))
all_stn=set(all_stn)
df=read_csv(yr+'.csv')
df.stn=[int(i) for i in df.stn]
col=df.columns[2:]
s=set(df.stn)
new=s-all_stn
old=all_stn-s
if len(old)>0:
print(old)
if len(new)>0:
df=df.loc[df.stn.map(lambda x:x not in new)].reset_index(drop=True)
程式重點說明
測站缺值之填入
- 在排序、轉成矩陣之前,需對測站是否不存在造成缺值情況進行處理。
- 此處以
pivot_table進行計數,篩出測站數不足的日數,先填入np.nan,再一併以fillna全部將np.nan改成負值,以利後續遮罩之應用。
nt,ns,ni=len(set(df.ymd)),len(set(df.stn)),len(col)
if len(df)!=nt*ns:
#sys.exit('time or station data missing!')
pv=pivot_table(df,index='ymd',values='stn',aggfunc='count').reset_index()
ymd_ng=list(pv.loc[pv.stn!=ns,'ymd'])
for i in ymd_ng:
ss=set(list(df.loc[df.ymd==i,'stn']))
for j in s-ss:
df1=DataFrame({'ymd':[i],'stn':[j]})
for c in col:
df1[c]=np.nan
df=df.append(df1,ignore_index=True)
輸入csv檔轉成矩陣
- 負值必須將其遮蔽
df=df.sort_values(['ymd','stn']).reset_index(drop=True)
df=df.fillna(-999)
dta=df.values
var=np.zeros(shape=(ni,nt,ns))
m=0
for t in range(nt):
var[:,t,:]=dta[m:m+ns,2:].T
m+=ns
var = np.ma.masked_where(var< 0, var)
測站編號與序號的對照
- 因測站編號不是從0開始,也會跳號,因此需以一個字典(
seqn)來記錄編號與序號的對照關係。
nw=len(twn)
twn=twn.sort_values(['new_code']).reset_index(drop=True)
seq=list(all_stn-old)
seq.sort()
seqn={seq[i]:i for i in range(len(seq))}
矩陣內積之執行
- 形成疏鬆矩陣fac,個別鄉鎮區的總和為1。
- 因
var矩陣中存在有缺值,是個遮蔽矩陣,因此必須使用np.ma.dot,否則只要有一個nan值,該日全部的鄉鎮區平均結果都會是nan
fac=np.zeros(shape=(ns,nw))
for t in range(nw):
n=len(twn.stns[t])
if n==0:sys.exit('no stations in this town')
for i in twn.stns[t]:
if i in old:continue
fac[seqn[i],t]=1/n
res=np.ma.dot(var,fac)
將矩陣轉為資料表
- 資料操作使用矩陣,表示的資料的維度具有規則性,即使改成資料表的型態,其內容也具有重複性,過去即以迴圈方式來進行複製。
- 此處使用1維的單位矩陣(unit matrix、
np.ones)即單位向量、與維度向量進行外積(np.outer),將維度向量(日期、鄉鎮區代碼)重複足夠多次,以使壓平後的總長度符合二者長度的乘積。 - 外積的定義
A[m] x B[n] = C[m,n](x為外積符號cross)
ymd=list(set(df.ymd));ymd.sort()
ymd=np.array(ymd,dtype=int)
one=np.ones(shape=(nw),dtype=int)
ymds=np.outer(ymd,one)
cod=list(set(twn.new_code));cod.sort()
cod=np.array(cod,dtype=int)
one=np.ones(shape=(nt),dtype=int)
cods=np.outer(one,cod)
dd=DataFrame({'ymd':ymds.flatten(),'TOWNCODE':cods.flatten()})
i=0
for c in col:
dd[c]=res[i,:,:].flatten()
dd.loc[dd[c]<0,c]=np.nan
i+=1
- 最終的維度順序仍然保持[日期,鄉鎮區]
- 外積2個向量、長度依序為m,n,則將會產生一個[m,n]的矩陣。因此順序非常重要。
- 日期向量(
ymd[m])外積時,必須在前、單位向量(one[n])在後 - 鄉鎮區向量外積時、必須單位向量(
one[m])在前、鄉鎮區向量(cod[n])在後 - 配合的單位向量長度,也必須有相應的長度。
- 日期向量(
- 相較過去迴圈的做法,此法減省非常多時間。
結果輸出
dd=dd.loc[dd.TOWNCODE>0].reset_index(drop=True)
dd.set_index('ymd').to_csv(yr+'res.csv')
結果檢視
- 因只有測站附近的鄉鎮區有值,位相鄰測站的其他鄉鎮區,則為空白
- 繪圖程式參geoplot繪製行政區範圍等值圖
程式下載
Download: stn_dot.py