LongChat
Table of contents
背景
- 這篇文章介紹了LongChat-7B和LongChat-13B這兩種聊天機器人模型,它們能處理高達16K tokens的長度文本。這些模型在長範圍檢索準確度上顯著優於其他開源模型,並且接近商業長文本模型的表現。LongChat模型除了可以處理長文本,還能精確地遵循人類指令並在人類偏好基準上表現出色。該團隊還分享了模型訓練方法和長文本處理的評估工具 。
Introduction and Summary
- 在這篇文章中,我們介紹了最新系列的聊天機器人模型 LongChat-7B 和 LongChat-13B,具有高達 16K 令牌的擴展上下文長度的新水平。評估結果表明,
- LongChat-13B的遠程檢索精度比MPT-7B-storywriter(84K)、MPT-30B-chat(8K)和ChatGLM2-6B(8k)等其他長上下文開放模型高出2倍之多。
- LongChat 在縮小開放模型和專有長上下文模型(例如 Claude-100K 和 GPT-4-32K)之間的差距方面顯示出了可喜的成果。
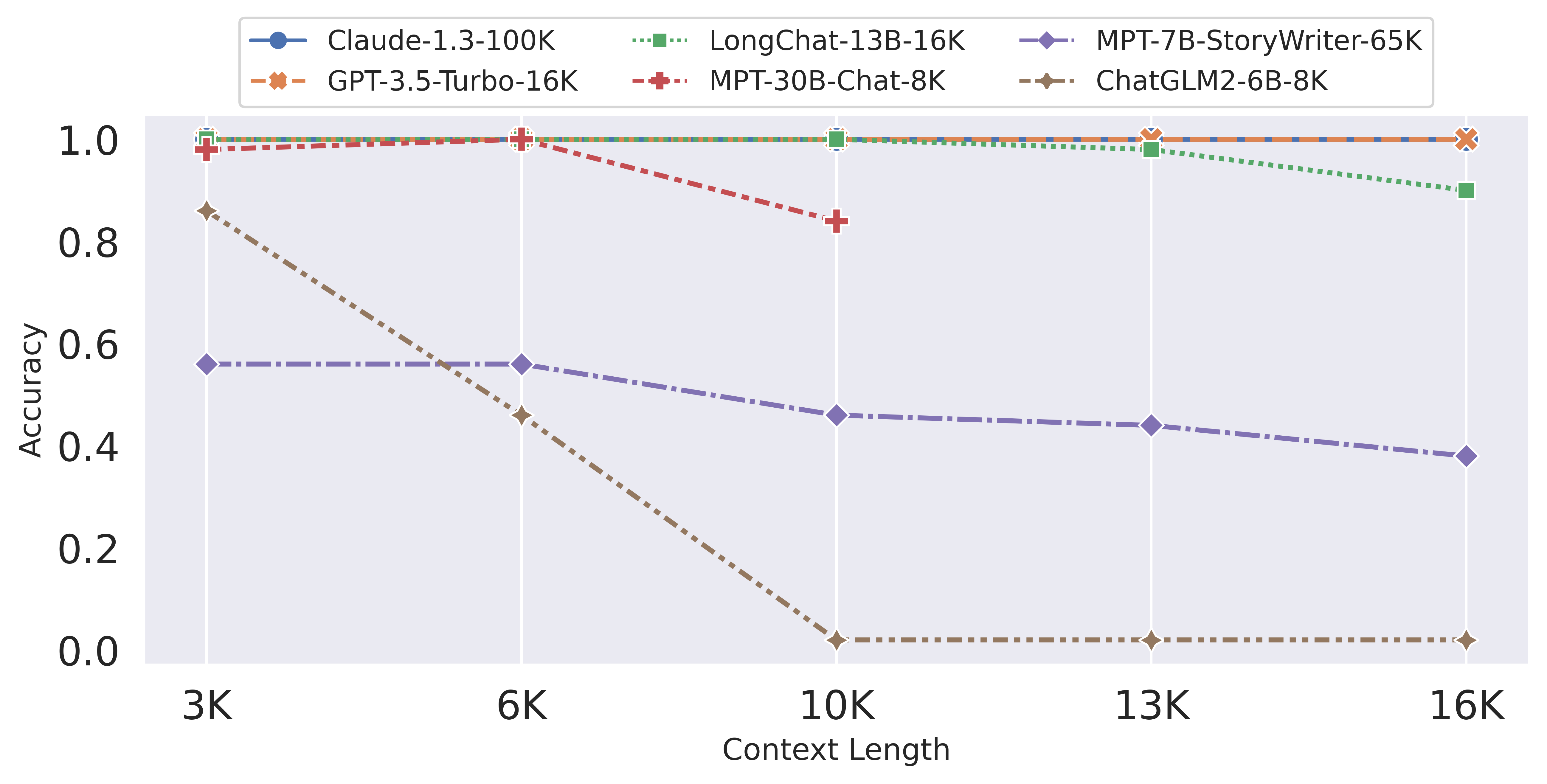 圖 1:在遠端主題檢索任務上將 LongChat 與其他模型進行比較。
圖 1:在遠端主題檢索任務上將 LongChat 與其他模型進行比較。
- LongChat 模型不僅可以處理如此長的上下文長度,還可以精確地遵循人類在對話中的指令,並在人類偏好基準MT-Bench中表現出強大的性能。
- 它們的預覽版本可在 HuggingFace 上找到:
lmsys/longchat-13b-16k和lmsys/longchat-7b-16k。可以使用 FastChat 在 CLI 或 Web 介面中進行測試:
python3 -m fastchat.serve.cli --model-path lmsys/longchat-7b-16k
開源社群對開發具有更長上下文的語言模型或擴展 LLaMA 等現有模型的上下文長度的興趣顯著增加。這種趨勢引發了各種有趣的觀察和廣泛的討論,例如Kaiokendev 的部落格和這份arXiv 手稿;同時,已經發布了幾個著名的模型,聲稱支援比 LLaMA 更長的上下文,值得注意的模型包括:
MPT-7B-storywriter支援 65K 上下文長度並推論至 84K。 MPT-30B-chat支援8K上下文長度。 ChatGLM2-6B支援 8K 上下文。
在 LMSYS Org,我們一直在同時探索各種技術來延長Vicuna等模型的脈絡。在這篇文章中,隨著 LongChat 系列的發布,我們分享了我們的評估工具來驗證法學碩士的長上下文能力。
使用我們的評估工具結合各種學術長上下文評估基準,我們對幾種聲稱支持長上下文的開源和商業模型進行了徹底的比較。透過此分析,我們檢查這些模型在其承諾的上下文長度上的表現如何。我們發現,雖然 GPT-3.5-turbo 等商業模型在我們的測試中表現良好,但許多開源模型並未在其承諾的上下文長度上提供預期結果。
用於重現部落格文章中的結果的資料和程式碼可在我們的 LongChat儲存庫中找到。我們在此筆記本中提供了視覺化。