轉換器transformers
Table of contents
背景
LLM 演進樹
source: from LLMsPracticalGuide
Transformer tutorial
- 轻松搞懂 Transformer(无代码版)、产品经理大群(发布于 2023-02-18 15:30)@知乎

source: Vaswani et. al 2017
超參數
- chatGPT的1750億參數,是怎麼算出來的? 為人民服務(編於 2023-06-21 15:41)@知乎
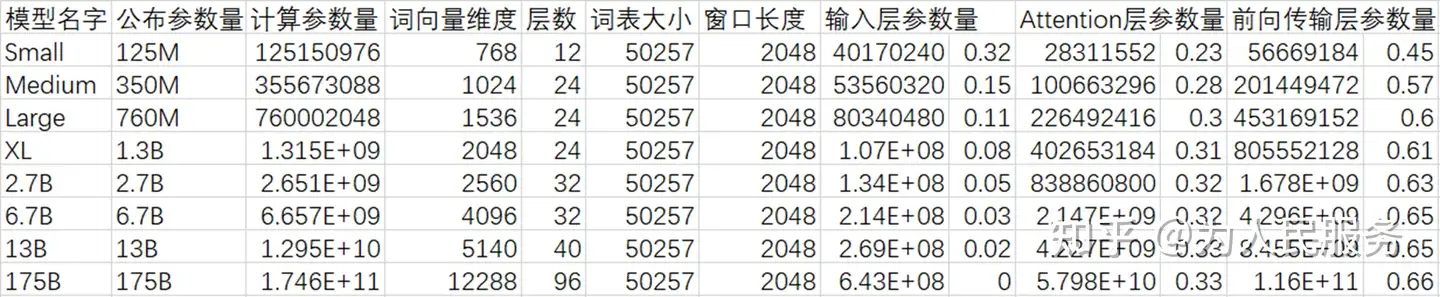
1)影響參數的主要變數有四個,其中影響最大的是詞向量維度(指數影響),其次是層數(高線性影響),最小的是詞表大小和視窗長度(低線性影響)。
2)輸入層參數量佔比最低,而且模型越大,佔比越低(在175B模型中幾乎可以忽略不計)。 在八個模型中,175B一般被稱為GPT-3模型。
3)前向傳播層參數量佔比最高,約為Attention層的2倍多一點點。
Learning By Doing
- 變形金剛與抱臉怪—NLP 應用開發之實戰 系列、大魔術熊貓工程師2022-09-16@2022 iThome 鐵人賽
- 花甲老頭學 AI 系列、老頭 2020-09-15 10:47:21@12th鐵人賽
- OH~ AI 原來如此,互助就此開始! 系列、henry_chen 2022-09-15 17:55:49@2022 iThome 鐵人賽
術語及名詞解釋
轉換器 Transformer
在自然語言處理(NLP)領域中,”transformer” 通常被翻譯為 “轉換器”。 這是一個比較直譯的翻譯,因為”transformer” 這個名稱本身就暗示了它的作用是將輸入數據轉換為輸出數據,而無需依賴傳統的遞歸神經網路(RNN)或卷積神經網路(CNN)結構 。
因此,”transformer” 模型在中文文獻和討論中通常被稱為 “轉換器” 模型。 這個名稱在中文NLP社群中被廣泛使用。 不過要注意,有時候也可能會看到其他類似的翻譯,但 “轉換器” 是最常見的。
Attention Is All You Need
“Attention Is All You Need” 是一篇重要的論文,由Vaswani等人於2017年發表,標誌著注意力機制的重大突破,對自然語言處理(NLP)和深度學習領域產生了深遠的影響。 這篇論文提出了一種新的神經網路架構,稱為Transformer,該架構是用於序列到序列(Sequence-to-Sequence,簡稱Seq2Seq)任務的基礎,如機器翻譯和文字摘要。
以下是關於”Attention Is All You Need”這篇論文的一些關鍵點:
Transformer 架構:這篇論文首次引入了Transformer 架構,它摒棄了傳統的循環神經網路(RNN)和卷積神經網路(CNN)等結構,採用了全新的注意力機制。 這一注意力機制允許模型在處理輸入序列時關注不同位置的信息,而無需依賴固定的滑動視窗或固定長度的視窗。
自註意力機制:Transformer 中的關鍵思想是自註意力機制(Self-Attention),它允許模型在同一輸入序列中的不同位置之間建立關聯。 這種機制有助於處理長距離依賴性問題,使得模型能夠更好地捕捉序列中的重要資訊。
多頭注意力:Transformer 引入了多頭注意力機制,允許模型在不同的表示子空間中進行多個自註意力運算。 這使得模型能夠同時學習不同抽象層級的資訊。
位置編碼:由於Transformer沒有RNN或CNN中的明確位置訊息,因此作者引入了位置編碼來幫助模型理解單字在序列中的位置。
廣泛應用:Transformer 架構已被廣泛應用於NLP任務,包括機器翻譯、文本生成、問答系統、文本分類等,並在各種比賽和應用中取得了巨大成功。
BERT 和GPT 等模型:”Attention Is All You Need” 的思想直接影響了後續的模型開發,如BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pre-trained Transformer),它們是 目前NLP領域的主要里程碑之一。
總而言之,”Attention Is All You Need” 論文對深度學習和自然語言處理領域產生了深遠的影響,開創了一種新的神經網路架構,並推動了NLP任務的發展。 這個論文的想法也被廣泛用於其他領域的序列建模和處理。
model bin files
公開的深度學習模型通常包含以下主要資訊資料:
模型權重(Model Weights):這是模型的核心,包含了經過訓練的神經網路的權重參數。 這些權重是模型透過訓練過程學到的,用於將輸入資料映射到輸出資料。 權重包含了模型在學習任務中所捕捉到的知識和模式。
模型結構(Model Architecture):模型結構描述了神經網路的架構,包括層(Layers)、激活函數(Activation Functions)、連接方式等資訊。 這些資訊定義了神經網路的拓撲結構,決定了訊號如何在網路中傳播。
模型配置(Model Configuration):這部分資料包含了模型的超參數和配置訊息,例如學習率、最佳化器類型、損失函數、輸入資料的形狀等。 這些配置參數對模型的訓練和推理過程非常重要。
元數據(Metadata):模型文件通常包含一些元數據,例如作者、許可證資訊、模型版本等。 這些元資料可以提供有關模型的額外資訊。
其他資源文件(Assets):有時,模型文件也包含一些輔助資源文件,如詞彙表(Vocabulary)、標籤映射(Label Mapping)等,這些資源有助於模型的使用和解釋。
總的來說,模型的二進位主要包含了模型的權重和結構,以及一些額外的配置和元資料。 這些檔案通常以常見的格式(如HDF5、TensorFlow SavedModel等)保存,以便在不同的深度學習框架中載入和使用。 模型文件的具體內容和組織方式可能會因框架和模型類型而異。