RAG Methodologies
Table of contents
背景
RAG? 訓練?還是微調?
RAG(Retrieval-Augmented Generation)算是一種在語言模型訓練過程中整合了檢索機制的方法,旨在改進生成的文本質量和相關性。RAG 結合了兩種主要的技術:語言模型和檢索系統。這種模型在處理每個查詢時,會先從一個大型的文檔集中檢索相關資訊,然後將這些資訊作為語言模型生成回答的一部分。
RAG 不單純是語言模型的訓練或微調,而是一種創新的方法,利用現有的語言模型和檢索技術的結合來生成回答。它通常使用已經訓練好的語言模型(如 GPT 或 BERT)和一個檢索系統,透過特定的結構將這兩者融合,以提升模型對於特定問題的理解和回答能力。
因此,RAG 可以視為在標準語言模型的基礎上,加入檢索機制來擴充模型的功能,使其在特定應用中表現更佳。这种结合让RAG在处理需要广泛背景知识的任务时,表现优于单独的语言模型。
RAG vs finetuning
語言模型能夠處理的 Token 數量越多,確實在某些方面可能降低微調的需求,但這並不是絕對的。模型處理更長的 Token 序列能夠帶來以下幾個好處:
1. 更好的上下文理解:模型如果能夠接受更長的輸入,意味著它能夠一次考慮更多的信息,從而更好地理解上下文。這對於理解長篇文章、進行復雜的對話交互等情況特別有用。
2. 降低資訊丟失:在較長的對話或文檔中,能處理更多的 Token 可以減少因截斷而導致的信息丟失。
然而,微調的必要性並不僅僅由能處理的 Token 數量決定:
• 特定領域的專業知識:即使語言模型能夠理解較長的文本,對於需要特定領域知識的任務(如醫學、法律或特定行業的應用),微調仍然是必要的。微調能夠讓模型更好地適應這些特定領域的語言用法和知識。
• 特定任務的性能提升:對於特定的應用或任務,如情感分析、問答系統等,即使模型可以處理更多的 Token,進行針對性的微調仍然可以進一步提升其性能,特別是在理解任務特定細節和語境上。
因此,能處理更多 Token 的模型在一定程度上可以減少對微調的依賴,特別是在不需要深入特定領域知識的通用任務中。但對於要求高精度或特定領域的應用,微調仍然非常重要。
RAG 方法論
work stream
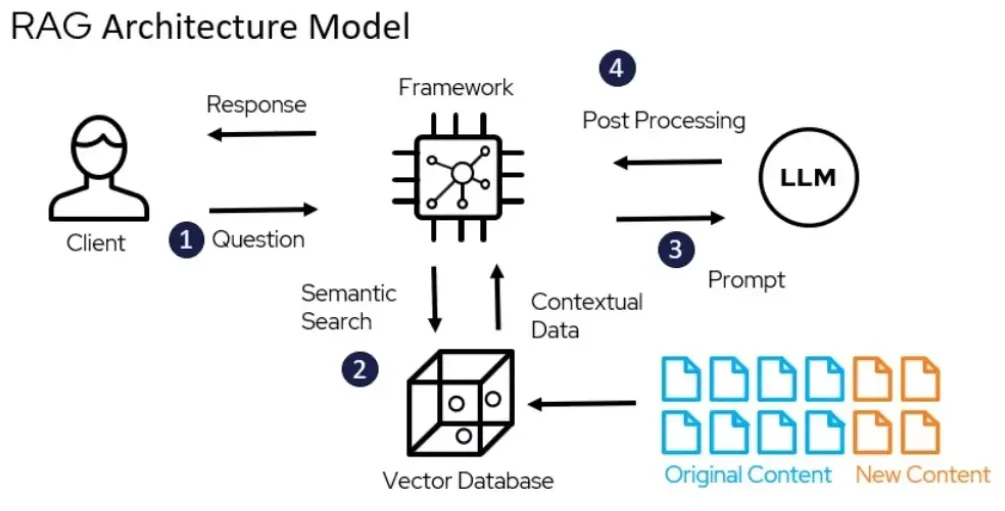
source: Designing high-performing RAG systems, by Bijit Ghosh, Mar 31, 2024@Medium
各階段選項
是的,RAG(Retrieval-Augmented Generation)存在著不同方法論的細節差異,這些差異主要體現在檢索機制、生成模型的選擇、以及檢索和生成部分的整合方式上。不同的實施方式可以根據應用場景和具體需求做出調整。
以下是 RAG 方法論中可能存在的細節差異:
- 文檔解析方式的差異,會有正確程度。目標在於
- 提高文本的乾淨程度、沒有穿插圖、表、照片等
- 提高語言解析能力。合理、易懂、語義連貫,含有豐富資訊的上下文。
- 正確格式的2維表格
- 符合LaTex格式的公式
- 能解析意義的圖、圖說、合理解釋的照片。
檢索方式的差異
• 稀疏檢索 vs. 密集檢索:
檢索與生成的結合方式
• 檢索後再生成:這是最常見的 RAG 模型方式,檢索到相關的文檔或片段後,將這些檢索結果作為上下文傳遞給生成模型,模型基於這些資料生成答案。 • 檢索引導生成:有些實現方式會在生成過程中不斷進行檢索。例如,在生成答案的同時動態地檢索更多的相關信息,以保證答案與檢索結果高度一致。 • 生成前的預處理:某些實施可能會先對檢索到的文檔進行一定的預處理或過濾,確保模型僅基於最相關的片段進行生成,從而提高生成的準確性。
生成模型的選擇
• 單一生成模型 vs. 多階段生成模型:RAG 可以使用單個生成模型來生成答案,也可以分成多個階段。例如,第一階段的生成模型根據檢索結果生成一個草稿,然後第二階段的模型進行精煉和修改。 • 不同的生成架構:基於不同生成架構(如 GPT、BART、T5)的 RAG 系統也會在生成效果上有所不同。某些生成模型可能擅長長文本生成,某些則更擅長準確地生成具體答案。
檢索文檔數量的設定
• 不同的實現方式會根據具體任務選擇不同的檢索文檔數量。某些實現會檢索大量文檔,然後由生成模型選擇性地從中生成答案;而有些會限制檢索到的文檔數量,以提高效率。
如何處理不相關或錯誤的檢索結果
• 檢索到的文檔可能不總是完全相關或正確。某些 RAG 方法會設計篩選機制來過濾不相關的檢索結果,以提高生成答案的準確性。而其他方法可能會讓生成模型自動判斷哪些檢索結果應該被忽略。
RAG 模型的訓練策略
• 在訓練 RAG 模型時,可以有不同的策略。有些實現會同時訓練檢索模型和生成模型,使兩者協同工作;而另一些實現則可能將兩部分獨立訓練,然後將它們組合在一起。
應用場景的不同
• RAG 系統在不同應用場景中也會有不同的實現。 例如,在問答系統中,RAG 的檢索重點是找到與問題最相關的文檔,而在生成新聞摘要等應用中,檢索部分則側重於找到最具代表性的信息來生成內容。
總結來說,RAG 的方法論可以根據具體的應用需求和技術選擇而產生差異,從檢索方法、檢索和生成的整合方式、到生成模型的架構,這些細節上的不同會影響 RAG 系統的最終性能。
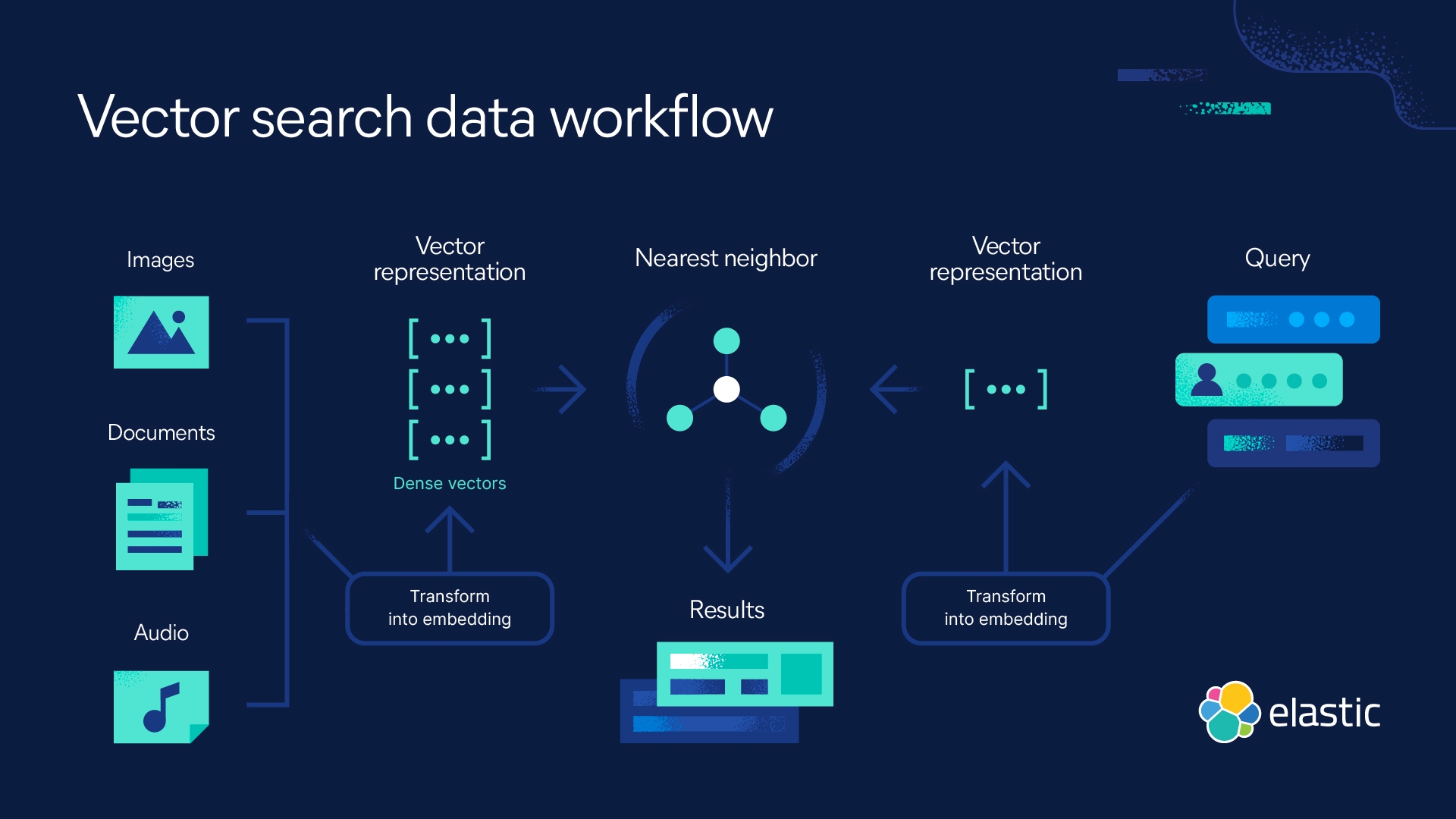
RAG的檢索
在 Retrieval-Augmented Generation (RAG) 中,稀疏檢索與密集檢索的選擇確實與資料庫的規模有密切關係,並且在不同規模的資料庫下,這兩種方法的優劣表現會有差異。至於這個規模門檻,通常可以用數量級來估算,根據經驗和技術特徵,大致有以下的數量級概念。
稀疏檢索(Sparse Retrieval)
稀疏檢索系統通常依賴傳統的倒排索引技術,如 Elasticsearch、Lucene、BM25 等。這類系統在檢索時不需要將文本向量化,而是基於關鍵詞匹配和統計方法來進行查詢。這種方式對於小到中等規模的資料庫表現出色,因為檢索過程相對輕量,且不需要大規模的內存或向量化處理。
- 適合的規模:
- 小型到中型資料庫:數千到數百萬級的文檔數量。
- 稀疏檢索在這些規模下能有效地通過倒排索引找到與查詢相關的文檔,並且索引時間和檢索時間都相對較短。
- 性能表現:
- 稀疏檢索的優勢在於速度快且對於小規模庫的查詢準確度較高,因為倒排索引的設計非常適合處理具體的關鍵詞檢索。
- 缺點:當資料庫擴展到更大規模時,基於關鍵詞的匹配可能無法處理語意上的模糊查詢,且與上下文相關的檢索能力有限。
密集檢索(Dense Retrieval)
密集檢索依賴於向量化技術,即將文檔和查詢轉換成向量表示,然後使用向量相似度(如 cosine similarity 或內積)來進行檢索。這種方法通常使用基於深度學習的模型來生成文檔和查詢的嵌入,如 BERT、Sentence-BERT、OpenAI Embeddings 等。
- 適合的規模:
- 中型到大型資料庫:數百萬到數十億級文檔。
- 密集檢索系統非常適合這些規模的資料庫,因為它能夠捕捉到更豐富的語意關聯性,尤其是當文檔數量龐大、文本內容較為複雜時。
- 性能表現:
- 密集檢索能夠解決稀疏檢索在語意上無法精確匹配的問題,即使查詢不完全包含文檔中的關鍵詞,也能通過向量相似度檢索到相關文檔。
- 缺點:密集檢索的計算成本較高,因為需要將每個文檔轉換為向量並進行相似度計算。如果文檔數量超過數百萬,實時檢索可能需要高效的 ANN (Approximate Nearest Neighbors) 搜索技術,如 FAISS 或 ScaNN。
規模門檻的概念
可以根據數量級的概念來劃分稀疏檢索與密集檢索的適用場景:
- 數千到數十萬級文檔:
- 稀疏檢索(BM25等):此規模下,關鍵詞匹配能夠滿足大部分查詢需求,並且計算資源消耗較少,檢索速度快。
- 數十萬到數百萬級文檔:
- 這是兩者的過渡區間。在此規模下,稀疏檢索仍具備一定的優勢,但當查詢語意複雜時,密集檢索能提供更高的準確性。如果文檔內容結構化程度較低(如長文本或複雜內容),可以考慮引入密集檢索。
- 數百萬到數億級文檔:
- 密集檢索變得更加合適。隨著資料庫規模的擴大,稀疏檢索的效率下降,而密集檢索可以更好地處理海量數據中的語意相關性。此時可以考慮使用像 FAISS 這樣的 ANN 框架來加速密集檢索。
- 數億到數十億級文檔:
- 在這個規模下,稀疏檢索已經難以滿足精確查詢的需求,特別是查詢語意模糊或資料庫結構複雜的情況。此時密集檢索成為主流方法,並且需要高度優化的向量化和檢索技術(如分片處理、集群化運算)來支撐查詢需求。
套件介紹
- elasticsearch
ragflow上使用8.11.3版本
總結
- 稀疏檢索在數千到數百萬級的文檔規模下具有很好的檢索效率,特別是對於具體關鍵詞查詢效果較好。
- 密集檢索在數百萬到數億級以上規模時,提供了更高的語意檢索能力和精度,尤其是面對複雜查詢或需要跨語意推理時表現更好。
具體選擇取決於資料庫的規模和查詢的語意複雜性,如果資料庫的規模達到數百萬以上,建議考慮使用密集檢索。
Terminology
TF-IDF
TF-IDF 是一種常用於文本分析和信息檢索領域的加權方法。它代表 “Term Frequency-Inverse Document Frequency”(詞頻-逆文檔頻率)。
TF-IDF 的主要思想是:
- 詞頻 (Term Frequency, TF):
- 衡量一個詞在某個文檔中出現的頻率。
- 頻率越高,表示該詞在該文檔中越重要。
- 逆文檔頻率 (Inverse Document Frequency, IDF):
- 衡量一個詞在整個文檔集合中出現的普遍程度。
- 一個詞如果在很多文檔中出現,則說明它不太具有區分度,IDF 值越低。
- TF-IDF 值:
- 將 TF 和 IDF 相乘得到 TF-IDF 值。
- TF-IDF 值越高,表示該詞在當前文檔中越重要。
TF-IDF 的主要應用包括:
- 文本摘要和關鍵詞提取
- 文檔相似度計算
- 垃圾郵件過濾
- 搜索引擎排名
通過 TF-IDF 可以突出一個文檔中最具有代表性和區分度的詞語,從而為各種文本分析和信息檢索任務提供有價值的特徵。
TF-IDF 是一種簡單但有效的加權方法,廣泛應用於自然語言處理和機器學習領域。
BM25
BM25 (Okapi BM25) 是一種基於 TF-IDF 的信息檢索評分函數。它是一種更加複雜和有效的文檔相關性評分算法。
BM25 的主要特點如下:
- 詞頻 (Term Frequency, TF):
- 與 TF-IDF 類似,考慮詞在文檔中出現的頻率。
- 但 BM25 使用了一個飽和函數,避免過度強調高頻詞。
- 逆文檔頻率 (Inverse Document Frequency, IDF):
- 與 TF-IDF 相同,考慮詞在整個文檔集合中的普遍程度。
- 文檔長度因素:
- BM25 引入了文檔長度因素,以補償長文檔天生有利的情況。
- 較短的文檔會獲得更高的相關性評分。
- 參數調整:
- BM25 有兩個可調參數 k1 和 b,用於調整 TF 和文檔長度因素的影響。
- 通過調整這兩個參數,可以針對不同的應用場景進行優化。
總的來說, BM25 是 TF-IDF 的一個改進版本,在處理詞頻和文檔長度方面更加優秀。它被廣泛應用於搜索引擎、推薦系統等信息檢索領域。
相比 TF-IDF, BM25 通常能提供更準確的文檔相關性評分,從而產生更好的搜索或推薦結果。