文檔解析
Table of contents
背景
- 正確解析出文檔的文本,對RAG的成功與否具有關鍵性影響。
- 使用者也可以自行清理文本、另以RAGFlow可以接受的格式輸入,也可以直接交付RAGFlow進行解析。如果是後者,會需要勾選
布局辨識。
RAGFlow提供的文檔解析
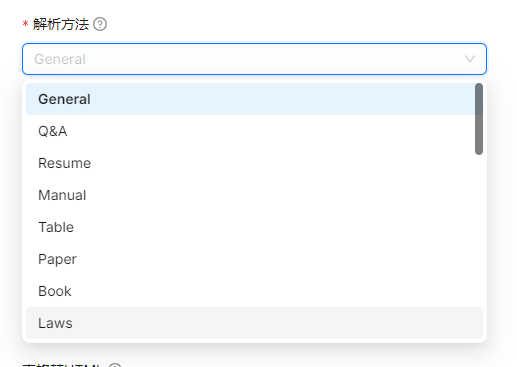
- 不同文檔類型的解析方式不同
- ragflow提供了下列11種方式,主要針對文章的樣式
- gereral: 一般性的文檔(DOCX、EXCEL、PPT、IMAGE、PDF、TXT、MD、JSON、EML、HTML)
- Q&A:一對一的段落關係
Ask: Q&A 分塊方法說明
此塊方法支持 excel 和 csv/txt 文件格式。
如果文件以 excel 格式,則應由兩個行組成 沒有標題:一個提出問題,另一個用於答案, 答案列之前的問題列。多工作表狀況,只要行列正確結構,就可以接受。
如果文件以 csv/txt 格式為 用作分開問題和答案的定界符。
未能遵循上述規則的文本行將被忽略,並且 每個問答對將被認為是一個獨特的部分。
- Resume:有必要的段落名稱
- Manual:有圖說
- Table:以\t作為分隔的TXT檔案
- Paper:2欄的特殊格式
- Book:除2欄的特殊格式,也有封面、目錄與圖表穿插
- Law:條文的架構、換行與斷句
- Presentation:一頁一塊(PDF、PPTX)
- One:整頁的簡介、一個檔一個塊。(DOCX、EXCEL、PDF、TXT)
- Knowledge Graph:零散的片段,需LLM另行組織者。(DOCX、EXCEL、PPT、IMAGE、PDF、TXT、MD、JSON、EML)
佈局識別
- 使用視覺模型進行佈局分析,以更好地識別文檔結構,找到標題、文本塊、圖像和表格的位置。如果沒有此功能,則只能獲取 PDF 的純文本。
- 佈局識別的原理,基本上也是個圖形辨識的AI模型,也會消耗GPU的算力。