Kmean方法應用案例分析
Table of contents
背景
- 類別的定義雖然是為解釋、比較上的方便,有其充分性,但如何以客觀的方式形成類別,為過去研究中最困難的部分。
- 另外,面對龐大的資料量,好的類別會幫助提升資料的趨中性,對於模型訓練以及提高特殊事件的預報度,則有其必要性。
- 此處總結過去kmean法的應用範例與結果,以及解題策略形成的過程考量。
軌跡線的類別分析
軌跡分析的背景
- 這項工作是整體三維軌跡分析的後處理部分,用以歸納並簡化逐時反軌跡分析的結果。
- 數據庫介紹與叢集策略
- 時間性
- 軌跡線是由軌跡點所組成,雖然每個軌跡點有其出現的特定時間,其時間解析度為15秒。範圍則視其個別特性而異,以D1東亞範圍而言,可能長達3~8天。
- 但因為在同一條軌跡線上,其時間特性並沒有討論的特色,歸併在該軌跡線到達測站的時刻。其解析度為1小時。
- 空間性
- 一條軌跡線上可能會出現4萬個點,2點的距離與風速有關,但不會超過500M。大氣領域而言屬於解析度比較高的數據。先將數據濃縮成每小時、空間解析度約2公里,其解析度已經是非常足夠了。
- 因此叢集化的工作似應集中在空間上的整併,過去曾經考量的方案包括
- 直接以軌跡尾端出現的行政區(大陸省分、其他國家的縣份)作為代表,途中路徑不計入、予以捨去。此法資訊量不足,過於簡略。
- 以軌跡通過的所有行政區為像量內容。此法雖可增加資訊,也足夠簡化,但可能每個軌跡的資訊長度不一,難以統整。
- 所有軌跡點按照時間分段,取其中的10點(小於10點的軌跡則不計入)。此法相較其他為最優。(至於為何10點視捨去情形決定)
- 時間性
- 取出之10點座標,做成2X10維的向量,再運用K-mean法進行叢集之萃取(詳km.py程式說明)
叢集數與分析結果(遠域)
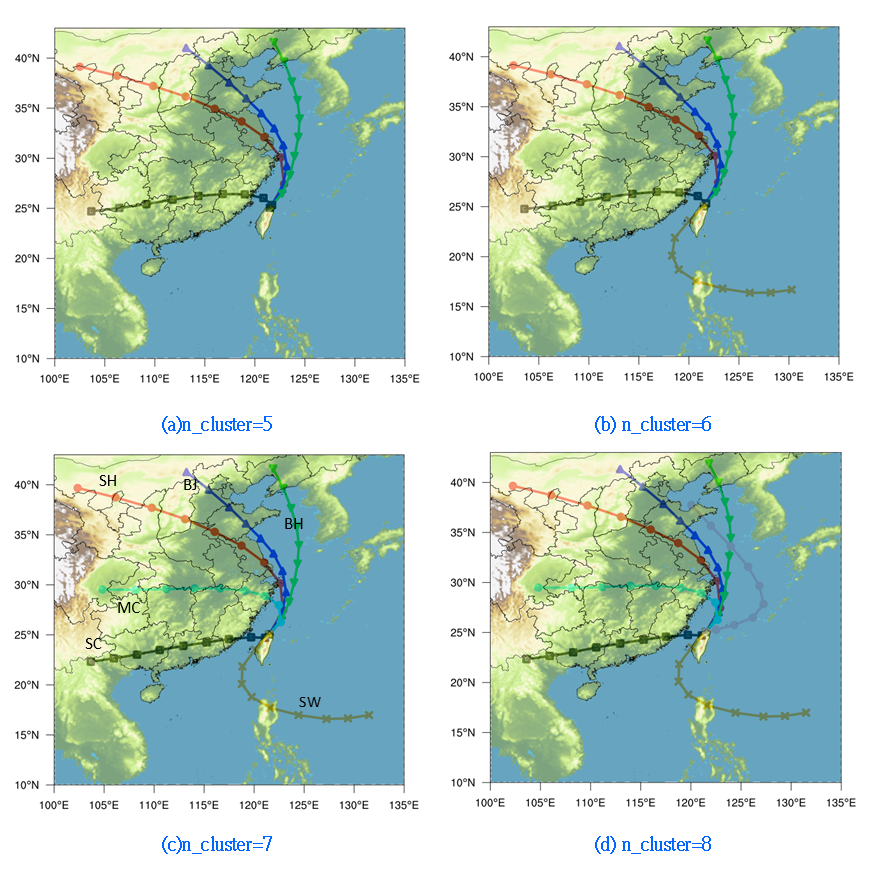 |
|---|
| 叢集數與反軌跡線叢集分析結果 |
- 10點取樣之檢討:由於取樣是按照時間(軌跡線總點數),叢集結果顯示各點似能保持均勻分布,而在轉向(風速較低)時顯示出有較密的分布、直線部分(風速較大)則較寬鬆。
- 叢集數之檢討:雖然叢集樹的決定完全是人為,不過此處也顯示過多的叢集數並不會提供更多的類別訊息,會出現相近類別的情形,如圖中的n值不足難以顯示有效的代表特性,n值7與8很明顯多出來的類別(山東半島轉偏東進入台北盆地),在解釋上也並不會提供特別的訊息。
- 各類別特性與區分(n值為7)
- SW:西南氣流。這類天氣型態一般發生在夏季,氣流來自太平洋向西,在巴士海峽轉向東北,途經台灣海峽南部、中部到達測站,因來自海洋,空氣品質可以保持在較佳的狀態。
- BH:來東北亞、渤海、黃海與東海來到台灣北部。這類軌跡多半是秋季東北季風剛剛轉換時的天氣型態。因軌跡來自海面,空氣品質也較佳。
- MC(華中)及SC(華南):大致上以中國南嶺為界,向東行進,前者沿著長江河谷,從四川向東自浙江出海,SC軌跡則大致沿著南嶺的南側,從越南的北部向東北行進,自福建南部出海至台灣北部。
- 西北(SH)、華北(BJ)與渤海(BH)3條軌跡大致上都是從台灣東北海面進到台灣北部陸地,BH軌跡以海面為主,前2者則以太行山及山東丘陵為界,分別向西北與華北延伸,向西北延伸軌跡通過上海,而華北軌跡通過北京。
- 這些結果顯示kmean法區分出來的類別,符合地形、海陸等地理與氣候學、氣流動力學等的特徵。
近域分析結果
- 前述提及對於較短的軌跡,有可能軌跡正好界於10~20點(軌跡點間距為1小時、為一日之內的軌跡),以kmean進行分類時會自成一個特殊的類別,春季(紅色)與冬季(藍色)結果如圖所示。
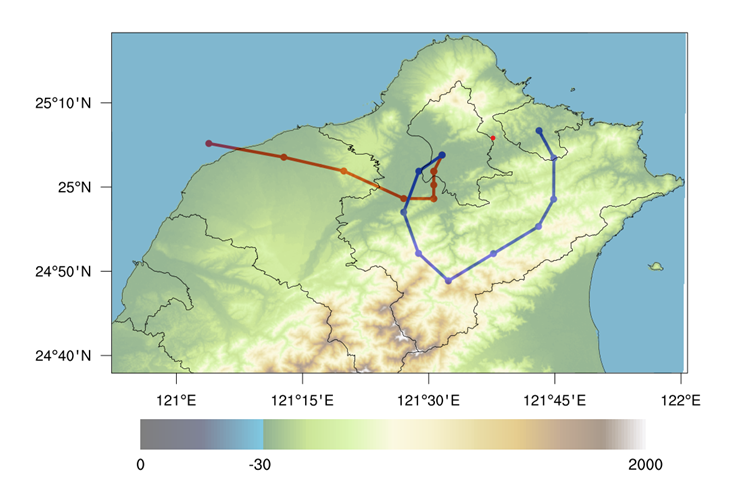 |
|---|
| 機器學習方法解析2017~2020年冬、春季臺灣北部近域氣團路徑。氣團軌跡終點為臺北盆地中的環保署中山站,高度50M,起點為觸地位置,高度為地面。藍色線為冬季分類結果,紅色線為春季結果,由於軌跡轉向時風速很慢,叢集結果有降低維度的傾向,點數不及10點。 |
- 春季自林口台地南側之海風進入盆地,頁間轉成北風,為新店溪之谷風。
- 冬季自基隆開始之山風,沿著雪山山脈北側達到福山一帶,夜間轉成下沉氣流下滑進入盆地。
- 再次顯示kmean所得之代表性軌跡,可以符合空氣動力學的特性。
測站污染時序特徵之分類
原理
- 每一天污染物尖峰濃度出現的時刻,與當地的擴散條件、影響測站的污染活動等等有密切的關係。一般而言,受都會區交通影響的測站,其汽機車排放之主要影響項目為氮氧化物與一氧化碳,會在清晨交通尖峰時間出現尖峰濃度。
- 隨著測站時間的累積,也可能會在其他時間出現尖峰濃度,因此其24小時的機率分布會是個隱含很多訊息的特徵性質。
- 按照發生尖峰濃度的機率,將24個小時進行排序,並組成向量進行叢集分析,可以有效將測站區分為受交通、工業、或餐飲業污染影響的測站,再進一步比較分析。

