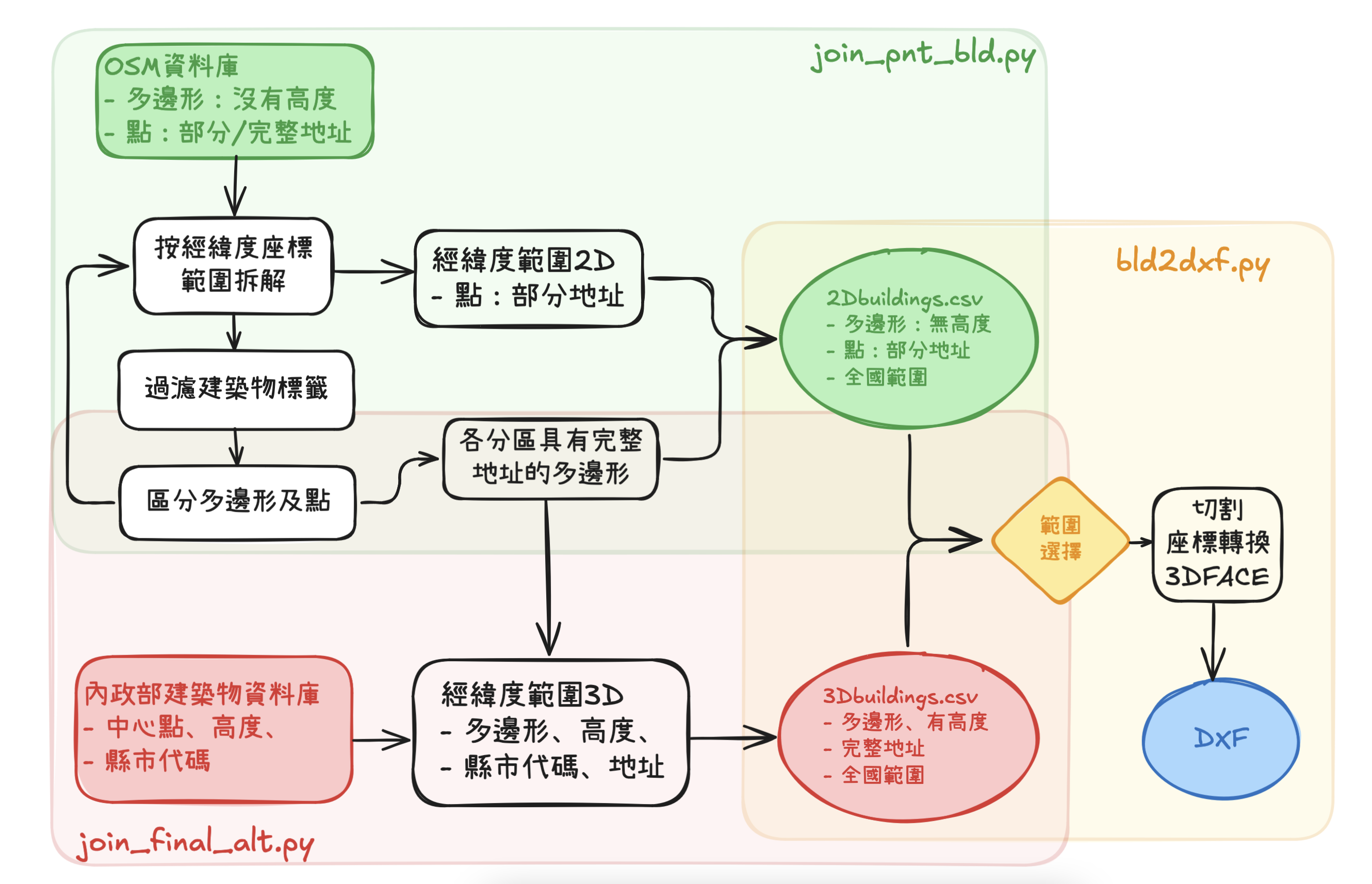
內政部3D建築物數據之處理
背景
- 內政部國土測繪中心多維度服務平台提供全台建築物位置與高度資訊,唯沒有建築物平面的相關訊息,需要與其他平面數據庫如OSM結合應用。
- 建築物命名與檔案切分方式不明,未來合併時以位置座標為參考即可,不需要其他資訊。檔案雖然很多,每個檔案並不是很大,可以平行處理以加速處理效率。
- 為加速整併,此處還是汲取其中的縣市代碼,以備與OSM數據中的地址快速結合。
檔案以KML型態儲存,然而並非典型的
kml格式,geopandas無法直接讀取,必須以xml.etree.ElementTree解析。- 以下為rd_mkl3.py的程式說明。
程式說明
這段程式碼的目的是將 KML (Keyhole Markup Language) 檔案轉換為 CSV 格式的檔案,便於進一步分析和使用。程式使用了 Python 的 pandas 和 xml.etree.ElementTree 模組來處理 KML 檔案中的地理數據。
輸入
- kml_folder: 包含多個 KML 檔案的資料夾路徑。
- output_csv: 輸出 CSV 檔案的名稱。
- 在此以所在(相對)目錄來定義輸入輸出檔案名稱,以目錄切換作業開啟同步執行。
輸出
- 一個 CSV 檔案(
output.csv),包含從所有 KML 檔案提取的數據,其中每一行代表一個Placemark的資訊。
重要邏輯
- KML 解析: 使用
xml.etree.ElementTree解析 KML 檔案,並尋找所有的Placemark元素。 - 數據提取:
- 提取每個
Placemark的名稱 (name)。 - 提取地理位置的經度 (
longitude) 和緯度 (latitude)。 - 提取相關的區域資料,像是
maxAltitude和COUNTY。
- 提取每個
- 數據整合: 將從所有 KML 檔案提取的數據合併成一個 Pandas DataFrame,並輸出為 CSV 檔案。
較艱澀語法的解釋
ns = {'kml': 'http://www.opengis.net/kml/2.2'}: 定義了命名空間,以便在解析 XML 時正確識別 KML 元素。placemark.find('.//kml:Model', ns): 使用 XPath 查找Model元素,這是 KML 中存放地理位置的部分。pd.concat(all_data, ignore_index=True): 將多個 DataFrame 合併為一個,並重新編排索引。
改進建議
- 錯誤處理: 加入對 KML 檔案解析的錯誤處理,以防止因單個檔案格式錯誤而中斷整體處理。
- 彈性輸出格式: 可以考慮添加選項,允許用戶選擇輸出的格式(如 JSON、Excel 等)。
- 參數化命令列: 使用
argparse模組使得用戶可以透過命令列輸入資料夾路徑和輸出檔案名稱,提高程式的靈活性。
程式之執行
同步執行與結果收穫
- 歷遍將各年度內政部檔案目錄
- 將kml檔案區分成20個子目錄(參考新創平行運作所需之次目錄)
- 移動到每個子目錄、在背景啟動每個子目錄下的rd_kml3.py工作
- 整併所有目錄的
output.csv成為一個大檔案、整理重複的檔頭,