OSM建築物多邊形與節點的整併(join_pnt_bld.py)
Table of contents
背景
- 整體建築物資料庫的整理、整併、與切割應用的工作流程如圖所示。
大致上整體工作區分為3大區塊。
join_pnt_bld.py的步驟屬於前期處理,為最終整併成3Dbuildings.csv的重要程序。OSM其他沒有高度的建築物資訊,則併入2Dbuildings.csv中,在找不到足夠3D資訊的時候可以作為替代。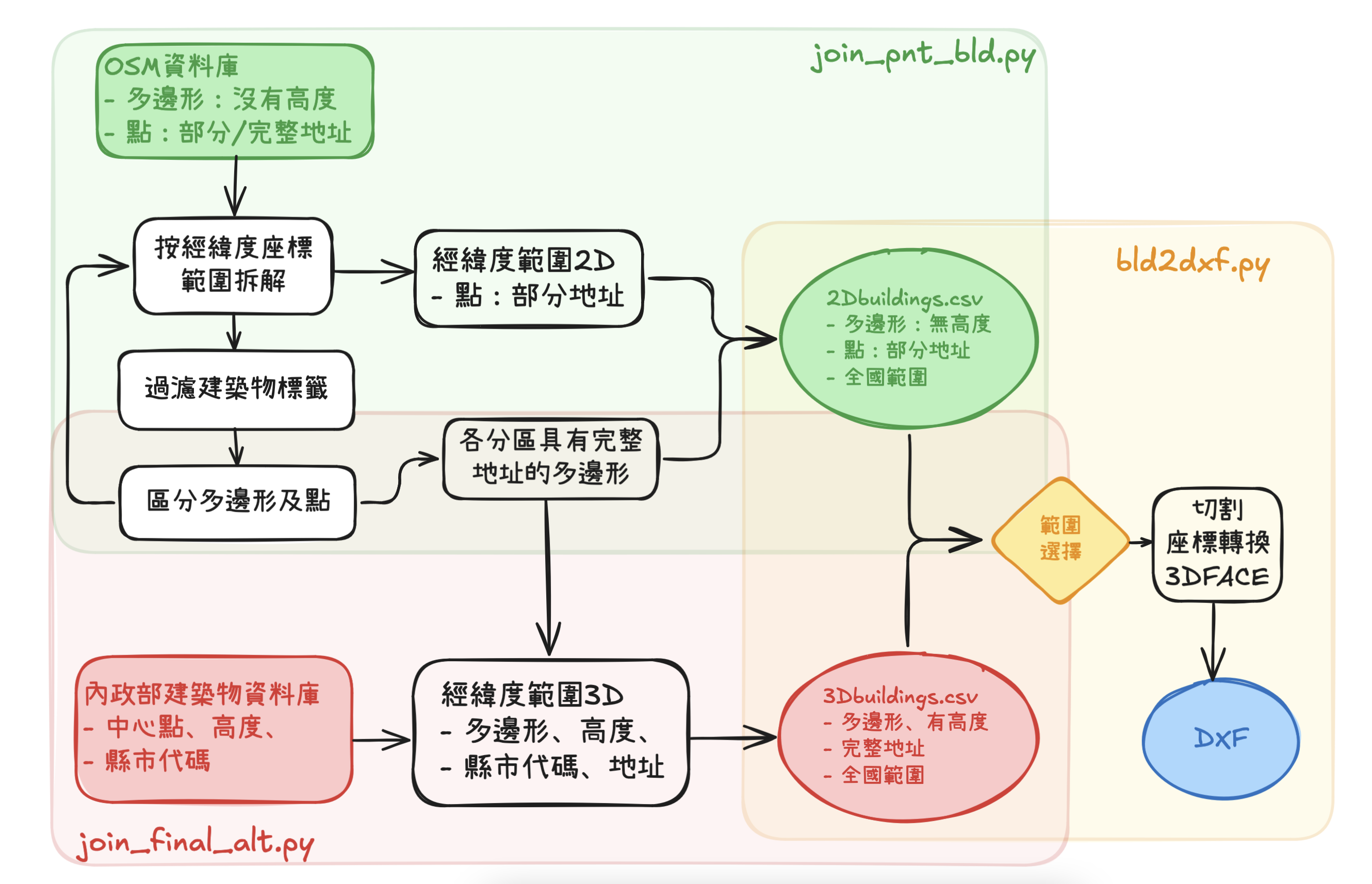
- 任務說明如下:
- 拆分taiwan.osm
- 過濾建築物標籤
- 區分多邊形與節點
- 從地址中可以辨識所在縣市之篩選
- 整合節點與多邊形
- 任務策略檢討說明如下
全台OSM數據的拆分策略
-任務說明
- OSM檔案是個ASCII檔,按順序區分為節點(
node)、道路(way含LineString及Polygon,MuitiPolygon),與關聯(relation)等3個段落。何以可以寫成這樣不理解,猜測應該是資料庫輸出的結果。 - 因為道路與關聯是用節點標籤來表示,如果在同一個程式內來處理檔案,會造成記憶體不足的衝擊,必須先行拆分。
- 拆分的官方建議:使用online服務(
overpass)、QGIS、使用osmconvert或ogr2ogr等命令列工具(參考GIS StackExchang的討論)。QGIS個人就不建議了,(猜)記憶體也會被卡死。
程式說明
這個程式使用 geopandas、rtree 和 shapely 來處理地理空間數據。它的主要功能是將點(points)與多邊形(polygons)進行空間查詢,找出哪些點位於哪些多邊形內,並將結果寫入 CSV 檔案。
輸入
程式接受兩個命令列參數,這兩個參數是 GeoDataFrame 檔案的路徑:
- 第一個檔案:包含節點的 GeoDataFrame。
- 第二個檔案:包含多邊形的 GeoDataFrame。
輸出
程式將生成兩個 CSV 檔案:
- 第一個檔案:包含匹配的點與多邊形的資料。這個索引的表格是用來檢核結果的正確性,並沒有後續應用的必要性。
- 第二個檔案:包含最終的多邊形與對應的地址資料。命名原則:
final_pnt_bld.csv('final'+sys.argv[1]+sys.argv[2])
重要邏輯s
- 讀取 GeoDataFrames: 使用
gpd.read_file()讀取點和多邊形資料。 - 幾何數據轉換: 將 GeoDataFrame 中的幾何列從字符串格式轉換為 Shapely 對象,以便進行空間運算。
- 創建 Rtree 索引: 使用
rtree包來創建一個 Rtree 索引,以加速空間查詢。 - 查詢 Rtree 索引: 對每個點,查詢 Rtree 索引以找出可能的多邊形,然後檢查這些多邊形是否包含該點。
- 生成結果 GeoDataFrame: 將匹配的點和多邊形的索引以及幾何資料存儲到一個新的 GeoDataFrame 中。
- 寫入 CSV: 將結果 GeoDataFrame 輸出為 CSV 檔案。
艱澀語法的解釋
apply(loads):這行代碼將loads函數應用到幾何列的每一個元素,將其從 WKT(Well-Known Text)格式轉換為 Shapely 幾何對象,這樣可以進行空間運算。idx.insert(i, geometry.bounds):這行代碼將多邊形的邊界(bounds)插入到 Rtree 索引中,以便後續進行快速查詢。idx.intersection(point.bounds):這行代碼查詢 Rtree 索引,返回與給定點邊界相交的所有多邊形的索引。
TODO’s
下載程式碼 join_pnt_bld.py
Download: 建築物DXF檔之改寫bld2dxf.py
改進建議
- 錯誤處理:增加對檔案讀取和轉換過程中的錯誤處理,以防止因為格式不正確或檔案不存在而導致程序崩潰。
- 增強輸出:可考慮將結果存儲為
GeoPackage或shapefile格式,保留地理信息。 - 性能優化:對於大型數據集,可以考慮使用平行處理來加快查詢速度。
- 使用函數封裝邏輯:將主要邏輯分為多個函數,這樣可以提高程式的可讀性和可維護性。
- 引入日誌功能:增加日誌功能以記錄程式運行狀態和錯誤,便於後續調試。