Druid查詢範例
Table of contents
背景
- Apache Druid伺服器是個高算力、適合大型資料庫的線上樞紐分析伺服器,已有成熟穩定的介面、使用簡單的SQL語言(自動產生程式碼、可供紀錄),操作容易。
- 伺服器本身同時具有資料庫伺服器、API伺服器、權限伺服器等等功能,適合作為發展平台。
- 伺服器可以使用到工作站80%的記憶體(240G among 300G)、47個核心(among 99)。
- 目前範例資料庫一年(2021年)約有130萬筆記錄、2016年迄今有352萬筆,未來還會增加中。
- 瀏覽器界面的詳細說明,詳見GUI介紹或官網Web console說明。
- 繪圖(explore)部分:由第三方網友提供,新版都納入頁面,詳見另一筆記說明。Apache的BI繪圖方案為superset
快速啟動
登入apache druid伺服器
- 打開Druid伺服器介面
- 目前尚未完整設定帳密系統。注意不要更動到資料庫(僅執行查詢功能)。
http://devp.sinotech-eng.com:8888/ (大環二)
http://dev2.sinotech-eng.com:8888/ (其他部門)
- 由瀏覽器介面登入
- 在url命令列貼上前述網址
- 瀏覽器(如chrome)會提示不是私人連線
- 輸入帳密
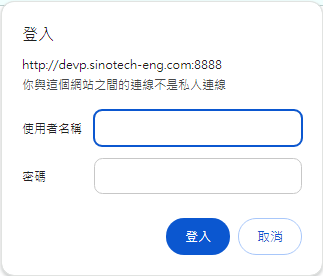
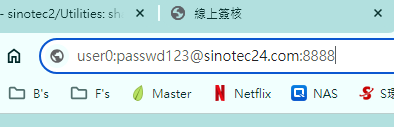
- 如何直接在url命令列輸入帳號密碼
- 先輸入帳號(範例中的user0)
- 間隔以冒號隔開(半形):
- 密碼
- 歸屬碼:@
- IP或domain name
- 端口:
:8888
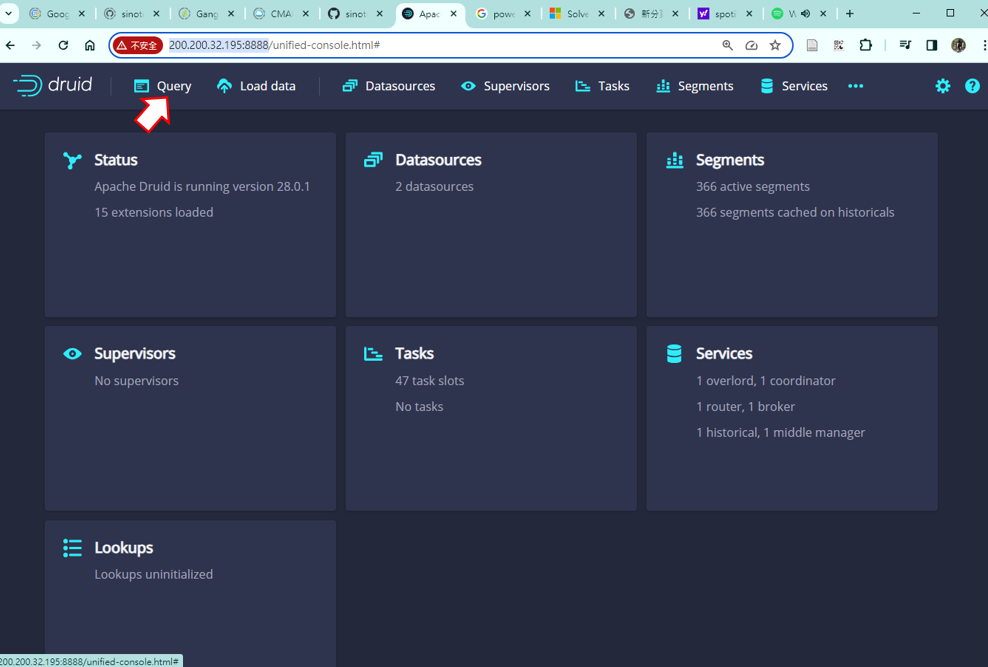
查詢界面
- 登入後按下查詢(Query)
- 左方出現資料表(如
df0_clean及wikipedia)、與資料表的各個欄位。有3種前綴:- A 為文字屬性
- 123 為整數
- 1.0 為實數
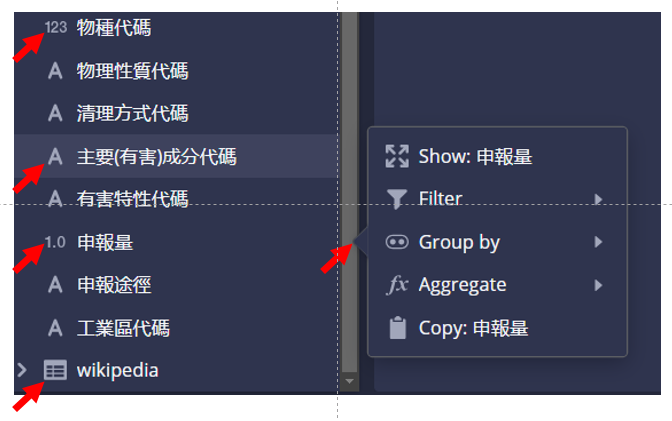
- 點擊欄位後,可進行簡易樞紐分析(會與程式碼輸入板連動)
- 顯示(Show):如無其他條件,則為計數(count)。 如有其他條件,則會增添至被選項目
- 篩選(Filter):文字、整數、實數(all)
- 群組(Group by):文字、整數
- 聚合(Aggregate):計數(文字)、大小、加總、平均、近似分位數(整、實數)、最新(all)
- 複製(Copy):複製欄位名稱到剪貼簿,以便在程式碼輸入板內編輯使用
- 中間上方為程式碼輸入板
- 按下
+開啟新的tab, - 貼上SQL程式碼、或執行欄位右鍵選項
- 按下
Run即可跑出結果。
- 按下
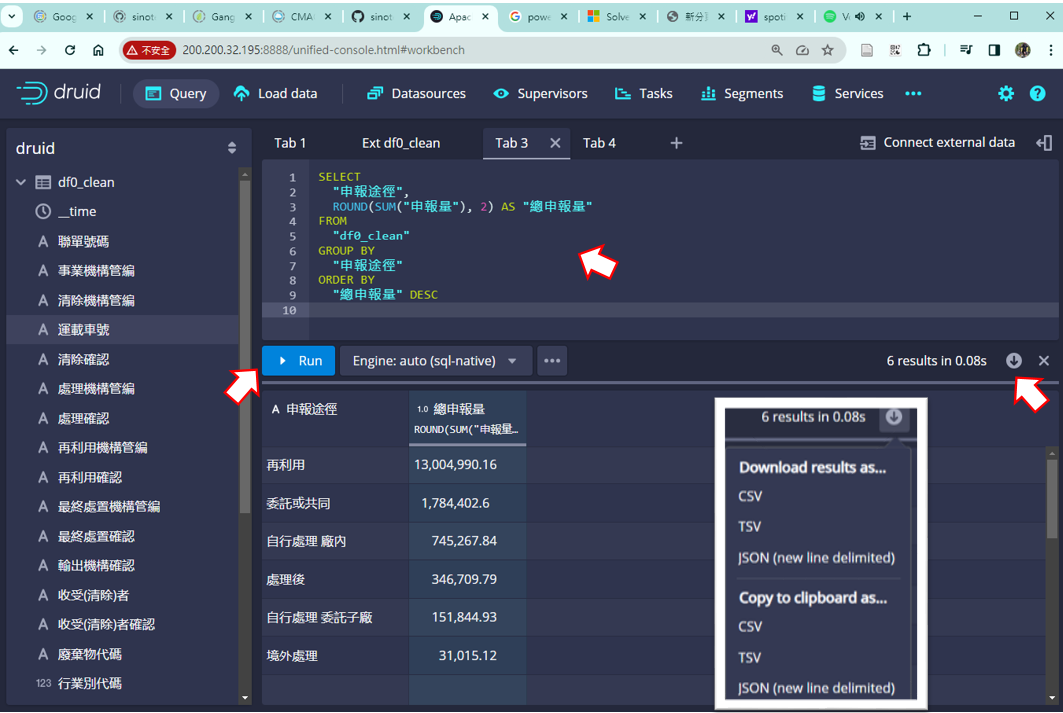
- 可以用自然語言在GPT上詢問
- 按下右方下載按鍵,將結果另存新檔。
計數
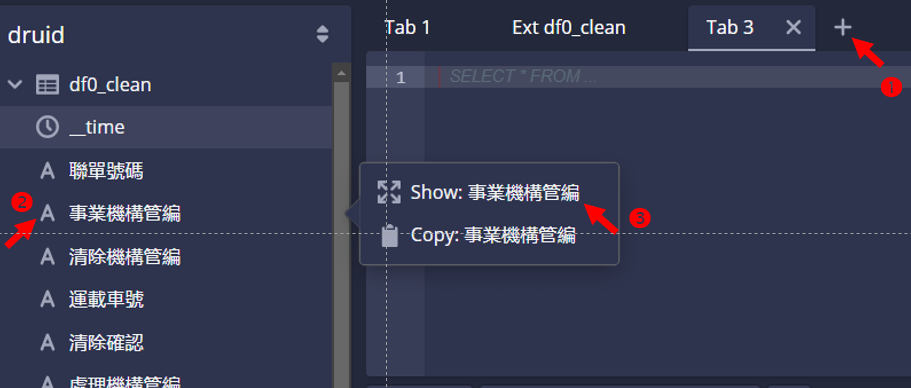
- 在程式碼輸入板上方點擊
+,出現空白輸入板、等候輸入查詢程式指令 - 點擊
事業機構管編欄位名稱,出現選項 - 點擊顯示(Show):會在程式碼輸入板出現程式碼
- 程式碼中的
1、2即為SELECT被選項目之順位、以1起算。
SELECT
"事業機構管編",
COUNT(*) AS "Count"
FROM "df0_clean"
GROUP BY 1
ORDER BY 2 DESC
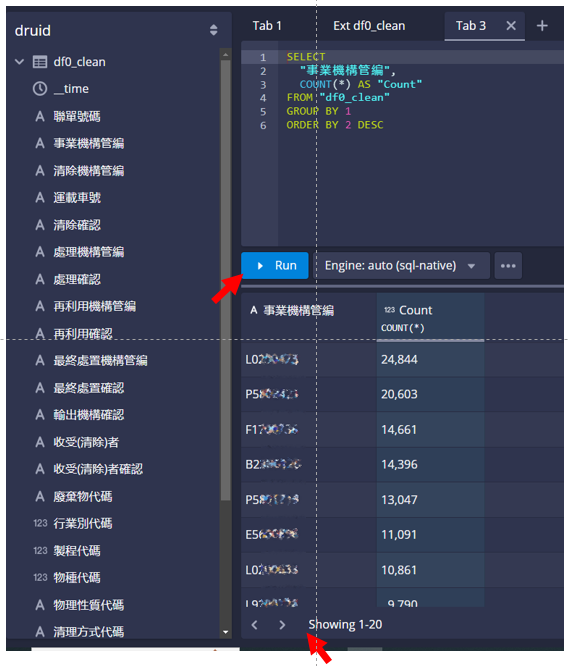
- 檢視程式碼、孰悉其意義、以利自然語言對話。
- 點擊
Run,即在下方結果看板出現事業機構管編群組的計數 - 按看板下方的
< >鍵,可翻看結果
查詢範例
群組加總
加總資料表df0_clean中”申報途徑”各種樣態的”申報量”,加總結果取到小數點以下2位,按照加總結果大小反向排序
SELECT
"申報途徑",
ROUND(SUM("申報量"), 2) AS "總申報量"
FROM
"df0_clean"
GROUP BY
"申報途徑"
ORDER BY
"總申報量" DESC
- 注意:druid不接受一般SQL語言之結尾標示(分號
;)。
過濾、群組、加總
我想了解資料表df0_clean中、”事業機構管編”為’L02**473’、各項”廢棄物代碼”的”申報量”加總結果,加總結果取到小數點以下2位,按照加總結果大小反向排序
SELECT
廢棄物代碼,
SUM(申報量) AS sum_申報量
FROM df0_clean
WHERE 事業機構管編 = 'L02**473'
GROUP BY 廢棄物代碼
ORDER BY sum_申報量 DESC
- druid沒有外卡(wild card
*之設定) - 從選單中來進行
- 先選要分區(group)的變數,一般是類別、字串足以分類之變數。
- 再選擇需統計(聚合)的變數。需選擇極大小、總和、平均等等。
3個維度的樞紐分析
SELECT項目事業機構管編:維度1申報途徑:維度2sum_申報量:維度3
SELECT "事業機構管編", "申報途徑", round(SUM("申報量"),2) AS "sum_申報量" FROM "df0_clean" GROUP BY 1,2 ORDER BY 3 DESC- 注意:不指定排序方式即為正向排序,如
ORDER BY 1。
龐大矩陣之樞紐
- 雖然這個題目本身是有問題的,但它同時也是挑戰各個資料庫軟體界面的容量與能力。
- 一般樞紐分析的目的,就在簡化資料表。如果一個800萬筆的資料表,如果縮減到30萬筆,這也是有縮減,但畢竟30萬筆的資料,仍然超過一般使用者可以理解的程度,還需要進一步再精簡。
- 實務面上,當pandas的欄數超過6個以上,不論資料的長短,就無法運作。
- Druid雖然可以運作以下SQL程式碼,結果也算正確,但因輸出超過1001筆,1002行以外的內容,系統界面將無法提供下載。
SELECT
EXTRACT(YEAR FROM TIME_FLOOR("__time", 'P1Y')) AS "year",
"工業區代碼", "事業機構管編", "行業別代碼", "清除機構管編",
"處理機構管編", "再利用機構管編", "最終處置機構管編","製程代碼",
"廢棄物代碼", "清理方式代碼", "縣市別", "申報途徑",
"廢棄物種類(一般&有害)",
round(SUM("申報量"),2) AS "sum_申報量"
FROM "df0_clean_112"
GROUP BY 1,2,3,4,5,6,7,8,9,10,11,12,13,14
ORDER BY 15 DESC
- 以下以API方式呼叫Druid Query,其結果可以包括整個樞紐表。呼叫方式:
- 使用者帳密:按照Druid的約定
- ${port}:執行Query的端口,一般為8888。
--data-binary:將會由檔案讀取API呼叫的內容設定- 可以指定
-o output2.json或將std output導向檔案,效果是一樣的。
curl -u admin:password1 -H 'Content-Type: application/json' -X POST http://${ip}:${port}/druid/v2/sql --data-binary @api2.json > output2.json
- json檔案名稱:api2.json,內容如下。注意:
- SQL指令中的雙引號,須加上反斜線,以避免混淆。
- 一般SQL可以不必特別指定雙引號,但使用API呼叫Druid似乎無法避免。
- json形式的SQL指令,不接受跳行指令,必須寫在同一行。
{
"query": "SELECT
EXTRACT(YEAR FROM TIME_FLOOR(\"__time\", 'P1Y')) AS \"year\",
\"工業區代碼\", \"事業機構管編\", \"行業別代碼\", \"清除機構管編\", \"處理機構管編\", \"再利用機構管編\", \"最終處置機構管編\",\"製程代碼\", \"廢棄物代碼\", \"清理方式代碼\", \"縣市別\", \"申報途徑\", \"廢棄物種類(一般&有害)\", round(SUM(\"申報量\"),2) AS \"sum_申報量\" FROM \"df0_clean_112\" GROUP BY 1,2,3,4,5,6,7,8,9,10,11,12,13,14 ORDER BY 15 DESC",
"context" : {"sqlQueryId" : "request01"},
"header" : true,
"typesHeader" : true,
"sqlTypesHeader" : true
}
查找與關聯
查找(LOOKUP)
- 這項作業是當我們以代碼為主軸進行樞紐分析,在結果中我們使用代碼與名稱的對照表,將名稱連到最後的結果表上,取代了代碼。
- excel與Druid稱此功能為查找,Access類似的功能為關聯(JOIN)。這2者的差別只在於前者的功能較強,但數量不能太大。後者則將對照表視為另一個資料表,而執行資料庫之間的串聯(JOIN)。
在Druid SQL中有一個特殊函式
LOOKUP可以直接使用,對於行數較小、經常改變的資料表進行快速的連結,而不需使用JOIN指令重新計算。SELECT LOOKUP(DF."工業區代碼", 'IndustrialArea') AS 工業區名稱, COUNT(*) AS "Count", ROUND(SUM("申報量"), 2) AS "sum_申報量" FROM "df0_clean_112" AS DF GROUP BY 1 ORDER BY 3 DESC- 範例中
LOOKUP函式的第一個變數,類似excel的lookup(),指得是實際執行樞紐分析時的維度,及申報量會以其為群組進行加總。 - 但是不同的是經過了
LOOKUP的對照轉換,換成以”工業區名稱”為表象。 - 最後結果中,將不再出現工業區代碼。
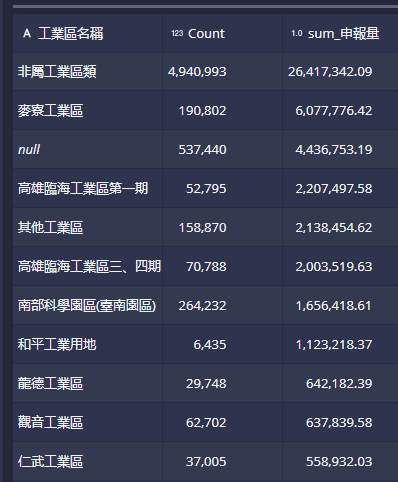
空品測站名稱查找
SELECT
stn2,
LOOKUP(CAST(stn2 AS CHAR(6)), '空品測站名稱') AS stn3,
COUNT(*) AS "Count",
ROUND(MAX("SO2"), 2) AS "max_SO2"
FROM (
SELECT
CAST(DF."stn" AS INTEGER) AS stn2,
DF."SO2"
FROM "all_yr" AS DF
) AS subquery
GROUP BY stn2
ORDER BY "Count" DESC
對照表之輸入與連結
- 對照表的產生詳見code_name.py
- 需在
./conf/druid/auto/_common/common.runtime.properties的外掛清單中增加"druid-lookups-cached-global" - 詳見官網的說明
- 介面:
- 由瀏覽列最右側3個點進入
- 按下新增,點選
json進入json檔案的設定
- json檔案模板與設定說明
- 避免使用中文檔名及欄位名稱,系統會不穩定。
"pollPeriod": "P1D",如果過度頻繁會造成系統不必要的負荷。"firstCacheTimeout": 500,單位是毫秒,因此如果檔案較大,須給足夠的時間上載數據。過大的對照表如數以萬計的「事業名稱表」,延長firstCacheTimeout似乎不會有幫助(還是需要使用JOIN,見資料表的關聯)。"uriPrefix":目錄位置"fileRegex":檔案名稱(規則)
{
"type": "cachedNamespace",
"extractionNamespace": {
"type": "uri",
"pollPeriod": "P1D",
"uriPrefix": "file:///nas2/sespub/epa_IWRMS/",
"fileRegex": "ChineseNameCleaningMethod.csv",
"namespaceParseSpec": {
"format": "csv",
"hasHeaderRow": true,
"columns": [
"key",
"value"
],
"keyColumn": "key",
"valueColumn": "value"
}
},
"firstCacheTimeout": 500,
"injective": true
}
Note: 對照表的注意事項:表中的鍵值,必須涵蓋所有資料庫中可能發生的情況,否則會發生錯誤。
資料表的關聯(JOIN)
- 關聯或串聯是資料表計算過程常用的手法,將A表中的某一個欄位,串到B表中,應用AB表中原本既有的關係,建立起新的關係,而不必另外定義對照關係。相較於前述的LOOKUP好處是:
- 不受限於資料表的行數
- 不必另外做對照關係、另存新檔
- 實務上的問題是:LOOKUP對照表更新時,如果資料表太長,載入的時間太長,過於LOOKUP表的更新頻率,此時,使用LOOKUP就不太切實際,使用JOIN就比較合理。
以下範例,旨在統計各個事業為單位群組的申報量(有46,551個事業),使用代碼、名稱是一樣的結果。但因資料表(
df0_clean_112)中並沒有重複儲存名稱,因此,連結到另一個代碼:名稱的對照表(BusinessOrganizationName),程式碼雖不如LOOKUP更簡潔、但因數量龐大,JOIN過程還是比較穩健。SELECT BusinessOrganizationName."value" AS 事業機構名稱, round(SUM(df0_clean_112.申報量),2) AS 申報量總和 FROM df0_clean_112 JOIN BusinessOrganizationName ON df0_clean_112.事業機構管編 = BusinessOrganizationName."key" GROUP BY 1 ORDER BY 2 DESC

時間標籤
- 時間標籤的處理是Druid強項之一。基本上Duid將資料表按照時間進行分段(Partition to Segments),來運用平行計算的功能,這是其計算的核心實力。
基本查詢
TIME_FLOOR指令將會擷取資料表中的時間標籤。- 第1個引數為資料表中的欄位
- 第2個引數為時間的篩取範圍:
PT1H(時)、P1D(日)、P1M(月)、P1Y(年)
SELECT TIME_FLOOR("__time", 'P1Y') AS "YEAR", COUNT(*) AS "Count", SUM("申報量") AS "sum_申報量" FROM "df0_clean_112" GROUP BY 1 ORDER BY 1 ASC
時間的篩選
在Druid SQL中,可以使用WHERE子句來進行時間範圍的篩選。 你可以透過比較__time欄位來實現時間過濾。 以下是一些範例:
特定日期的過濾:
SELECT * FROM your_table WHERE __time = TIMESTAMP '2022-02-14T12:34:56'在特定日期之後的過濾:
SELECT * FROM your_table WHERE __time > TIMESTAMP '2022-02-14T00:00:00'在特定日期之前的過濾:
SELECT * FROM your_table WHERE __time < TIMESTAMP '2022-02-14T00:00:00'在特定日期範圍內的過濾:
SELECT * FROM your_table WHERE __time >= TIMESTAMP '2022-02-14T00:00:00' AND __time < TIMESTAMP '2022-02-15T00:00:00'
確保在查詢中使用正確的時間戳記格式,並根據你的需求調整時間範圍。
時間標籤的萃取
- Druid時間標籤的內容到萬分之一秒,如果要萃取特定層級的時間值,可以用
EXTRACT指令,用法如下。
EXTRACT(YEAR FROM TIME_FLOOR("__time", 'P1Y')) AS "year",
EXTRACT還有其他的可能用法:YEAR: 年份、QUARTER: 季度、MONTH: 月份、WEEK: 星期、DAY: 天、HOUR: 小时、MINUTE: 分钟、SECOND: 秒等等。
重整與轉置
- 基本上SQL並不是一個完整的程式語言,如果要將查詢結果進行重整與轉置(re_indexing),可能必須分階段、以手工方式來執行。
- 雖然Druid SQL可以接受WITH指令,可以將階段處理過的資料表再行呼叫,但過程並不是很順暢,建議還是使用複製、貼上會比較妥當。
- GPT有建議將階段結果另存新檔(PC)再讀進Druid記憶體中(Linux)。但因涉及PC/Linux檔案系統的屏障,此途也不是很容易。
- 以下範例將2維(申報量前5大事業機構之年分布)的查詢結果予以轉置。
先執行所有年份的總申報量,取前5大事業機構。結果為5個事業機構管編。
SELECT 事業機構管編 FROM "df0_clean_112" GROUP BY 1 ORDER BY SUM("申報量") DESC LIMIT 5將管編做為篩選條件,列出各年分的加總量
SELECT TIME_FLOOR("__time", 'P1Y') AS "year", SUM("申報量") AS "sum_申報量" FROM "df0_clean_112" WHERE 事業機構管編 = 'L02**473' GROUP BY 1 ORDER BY 1 ASC- SQL不會執行迴圈,因此需要將管編填入程式碼的篩選條件以及欄位名稱位置。
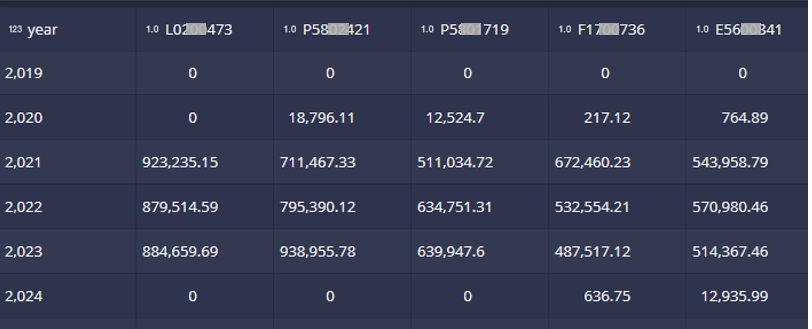
最後的程式碼
SELECT EXTRACT(YEAR FROM TIME_FLOOR("__time", 'P1Y')) AS "year", round(SUM(CASE WHEN a.事業機構管編 = 'L02**473' THEN a."申報量" ELSE 0 END),2) AS L02**473, round(SUM(CASE WHEN a.事業機構管編 = 'P58**421' THEN a."申報量" ELSE 0 END),2) AS P58**2421, round(SUM(CASE WHEN a.事業機構管編 = 'P58**719' THEN a."申報量" ELSE 0 END),2) AS P58**719, round(SUM(CASE WHEN a.事業機構管編 = 'F17**736' THEN a."申報量" ELSE 0 END),2) AS F17**736, round(SUM(CASE WHEN a.事業機構管編 = 'E56**841' THEN a."申報量" ELSE 0 END),2) AS E56**841 FROM "df0_clean_112" AS a GROUP BY 1 ORDER BY 1 ASC
連結與解除資料表
檔案管理
- 果要加(連結)資料,要先copy到/nas1或/nas2,window上的檔案系統工作站是看不懂得。
- 會需要設定SAMBA(洽linux管理員群組)
- 設定目錄與檔案的群組為:
SESAir - 可以使用cgi-python程式(見網址),上載檔案到
/nas2/druid_csv目錄下。- 這個網頁只處理csv檔案
- 請自行備份檔案
- 網頁連結到dev2的Druid實例(2023年之28版)
- Druid可接受檔案格式
- JSON Lines(gz壓縮亦可)
- CSV(逗號或分號)
- TSV(tab、
\t分隔) - Parquet(from Apache Spark、Apache Hive高效壓縮)
- ORC(Optimized Row Columnar),Apache Hive倉儲
- Avro(Apache Avro 二進位檔)
- Any line format that can be parsed with a custom regular expression (regex)
連結外部檔案
- Apache Druid可以接受多種資料的連結,包括雲端及本地、在線或離線,此處集中在以事後分析為主的需求,即批次式、本地磁碟機為連結對象。
- 連結可以直接在查詢(Query)程式碼輸入板的右方Connect external data(下圖)、或本地檔案(Local Data)畫面進行。檔案格式及連結方式都是一樣。
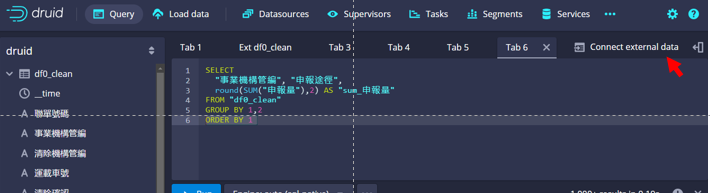
- 自本地檔案(Local Data)畫面進入檔案連結
- 下拉選單點選Batch SQL以SQL程式批次進行連結
- 點選本地磁碟機來源(Local disk):指得是工作站連結得到的網路磁碟機(/nas1、/nas2等)。
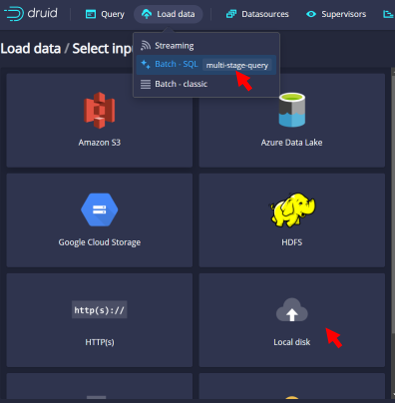
- 輸入目錄及檔名
- 必須輸入絕對目錄。(相對目錄只接受管理者之家目錄)
- 直接輸入檔名,或由右側下拉選單選擇檔案格式進行篩選、
- 找到檔名後,按下Connect data,進行數據上載。
- 解讀檔案格式
- 如果是太單純的csv檔案,系統會需要使用者確認格式。
- 內設是正則文字檔(
regex),可以右邊的下拉選單選擇csv - 選擇
csv後,其他既設選項都會隨之改變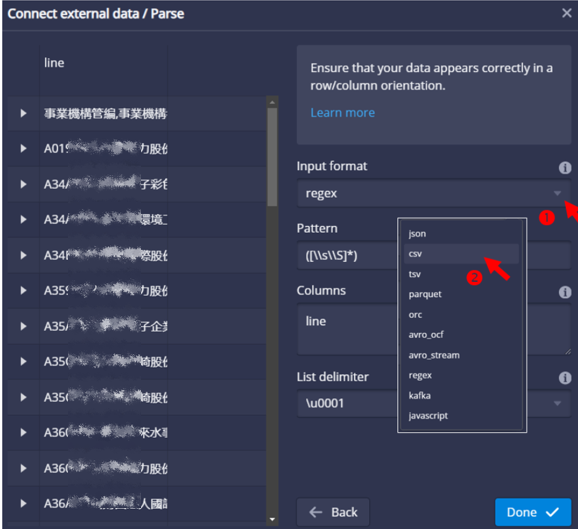
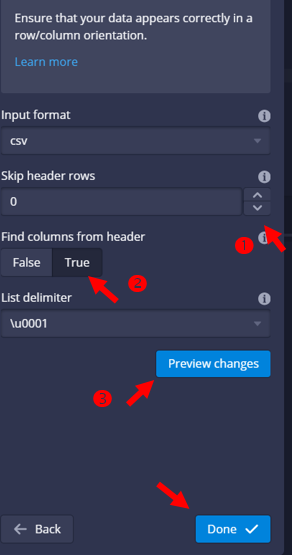
- csv檔案設定
- 表頭:系統會自動跳開表頭,如果要多跳行,需要設定1行以上。
- 是否由表頭對應到欄位名稱:選擇True。(druid可接受中文欄位名稱)
- 跳脫指令: Unicode 字符,0為尾端跳脫,1為開頭跳脫。(似乎不會影響結果)
- 預覽(Preview):檢視如果解讀正確,即可點選Done
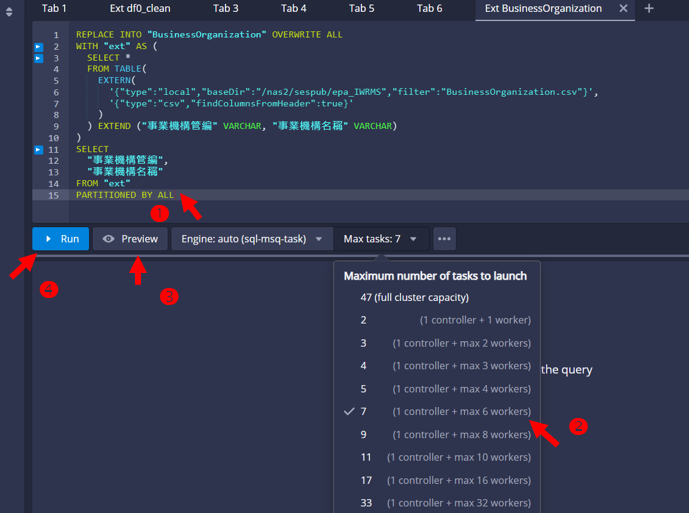
- 檢查載入程式碼
- 系統會讀取資料表的欄位名稱,提供程式碼在程式碼輸入板
- 除了確認欄位是否都要載入,也要確認是否每一欄都要能做區分(PARTITIONED、可分群組)。
- 如果不需要,直接刪除就不會執行載入,可減省記憶體。
REPLACE INTO "BusinessOrganization" OVERWRITE ALL WITH "ext" AS ( SELECT * FROM TABLE( EXTERN( '{"type":"local","baseDir":"/nas2/sespub/epa_IWRMS","filter":"BusinessOrganization.csv"}', '{"type":"csv","findColumnsFromHeader":true}' ) ) EXTEND ("事業機構管編" VARCHAR, "事業機構名稱" VARCHAR) ) SELECT "事業機構管編", "事業機構名稱" FROM "ext" PARTITIONED BY ALL - 確認使用計算資源(Max tasks)
- 如果沒有指定,系統會自行規畫最大上限。以devp工作站而言,會規畫一半的核心給這個資料表。這將會造成使用容量的限制及競爭。
- 如果表格不大、使用人數不多,規劃小量的算力即可。
- 預覽(Preview)
- 執行(Run)
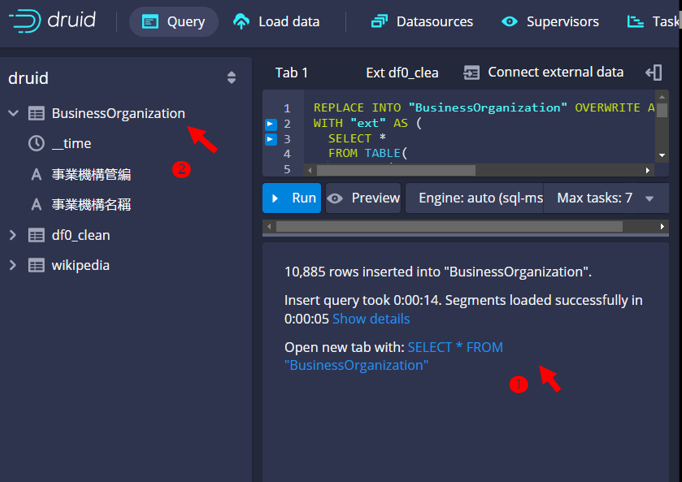
- 執行成功
- 檢查結果看板:會報告資料表的長度、花費時間、程式碼建議等等
- 也會在左側增加新的一個資料表、可展開個別欄位名稱,也可以正常查詢。
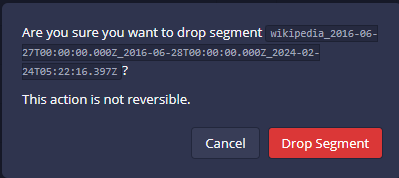
解除資料表的段落(drop segment)
- 基本上Druid介面提供的功能大多是即時查詢、控制檔案的連結、以及監管執行任務,並沒有提供修改、新增、刪除等界面
- 要解除一個資料源的連結,界面也不是很方便,應該是不希望常常做這種事。
- 具有權限的使用者,可以由段落(Segments)的刪除,來執行資料連結的解除
- 進入資料源(Datasources)
- 將段落標示為停用(unused)
- 經停用的段落予以刪除(解除連結),同時也會停止使用該段落數據的分析任務。
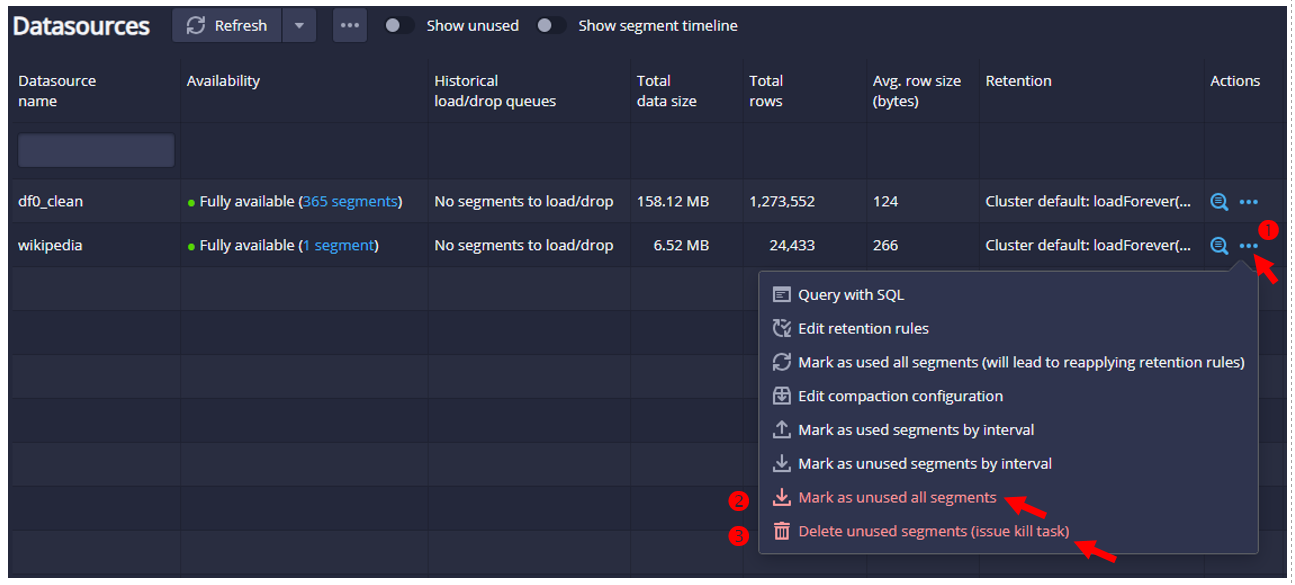
- 停用之後,就不會出現在資料源的畫面上,也不會出現在查詢的頁面上供大家查詢。
- 即使在資料源(Datasources)的界面上,也要按下顯示按鍵,才會顯示。
- 如要要刪除連結,還需要在Action的選項中執行。
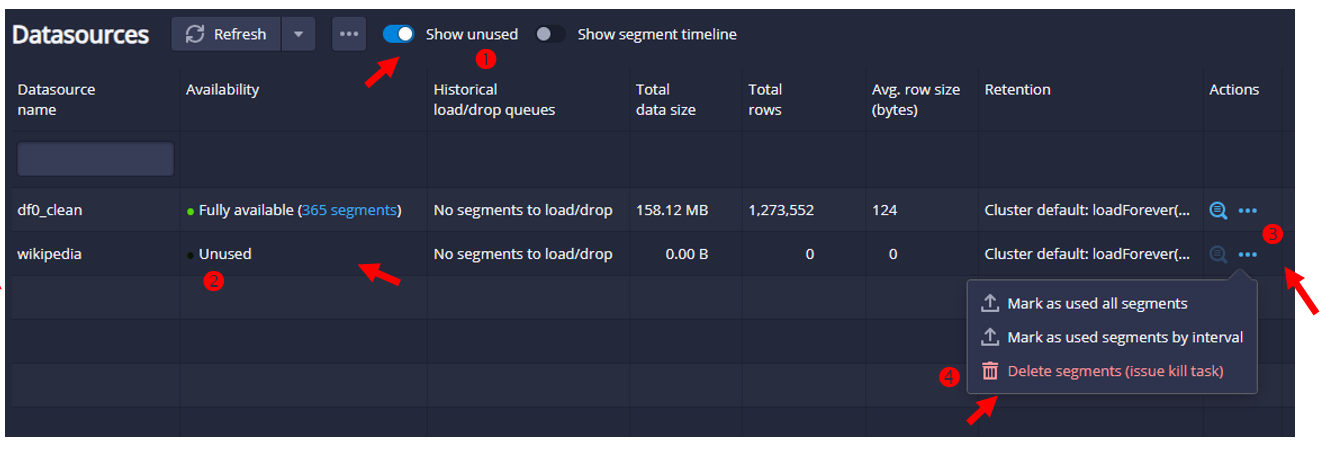
- 直接從Segments頁面也可以一個個段落進行刪除